

Articles • by Edwin Sanchez • March 28, 2024
ETL, or Extract, Transform, Load, is a 3-stage data integration process that involves gathering data from various sources, reshaping it, and loading it into a target destination.
Sources can be of different data formats. Examples are flat files, relational databases, or cloud data. These sources are reshaped or transformed so they map to the data columns of the target. Data warehouses are typical targets. But it can also be data lakes or another system.
ETL can either be batched or near-real time. Batched processing is the traditional way of processing data in chunks. It also runs on a set schedule. But near real-time processing offers quicker insights compared to batch-oriented ETL.
Since its start in the 1970s, ETL has evolved into a pivotal process. It adapted to the changing landscape of business needs. Today, ETL plays a crucial role in unleashing the power of Business Intelligence (BI). It also propels data analytics forward.
In this article, we will delve into the intricacies of ETL. We will explore how it works and many of the things you need to start working on an ETL project.
Why is ETL Important?
Understanding the pivotal role of ETL is essential. It offers benefits that drive informed decision-making and operational excellence.
Here they are:
- Data Consistency: ETL ensures uniformity by transforming data into a consistent format. The result fosters accuracy across the organization.
-
Business Intelligence Boost: It enables organizations to extract valuable insights from their data, fostering strategic decision-making.
-
Operational Efficiency: By automating the extraction and transformation processes, ETL enhances operational efficiency. So, it saves time and resources.
-
Holistic Data Integration: It harmonizes diverse data sources and creates a unified view. So, that facilitates comprehensive analysis and reporting.
-
Data Quality Assurance: Through its meticulous processes, it safeguards data quality. The result is minimal errors and enhanced reliability of analytical outcomes.

How ETL Works
How the ETL process works is obvious from the acronym itself. The image below describes it.
Let's expand this 3-stage data integration process below:
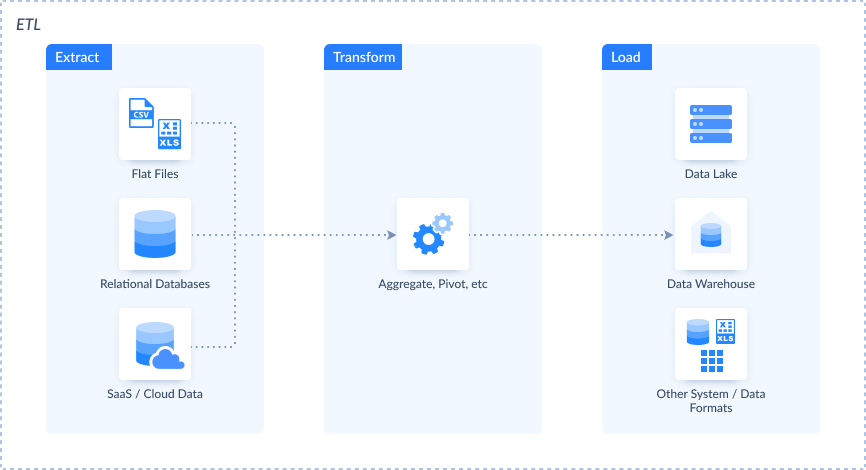
Extract
- Overview:
- The first step is extraction. Data is retrieved from various sources such as databases, files, or APIs.
- Process:
- Extraction involves identifying the relevant datasets and extracting the data. Then, it prepares it for the transformation phase.
- Example:
- Extracting customer information from Salesforce.
Transform
- Overview:
- Transformation is the core of ETL. Extracted data undergoes modifications to meet desired standards or requirements. The target repository dictates what transformations to use.
- Common Methods:
-
- Cleaning: Removing inconsistencies and errors from the data.
- Aggregation: Combining and summarizing data for meaningful insights.
- Formatting: Standardizing data formats for consistency.
- Pivoting: Transposing row data to become column data.
- Example:
- Converting sales dates from different time zones to a single, standard format.
Extract
- Overview:
- Process:
- Loading involves placing the transformed data into the designated repository, ready for analysis.
- Example:
- Uploading cleaned and formatted customer data into a data warehouse for further analysis.
-
The final step is loading. Transformed data is stored in the target destination. Typically, it's a data warehouse or database. The transformed data columns map to their target counterparts using data mapping.
In essence, ETL seamlessly progresses through these three steps — Extract, Transform, and Load — orchestrating the journey of raw data from source to a structured, usable format in a target repository.
How ETL Compares to Other Data Integration Methods
ETL vs. ELT (Extract, Load, Transform)
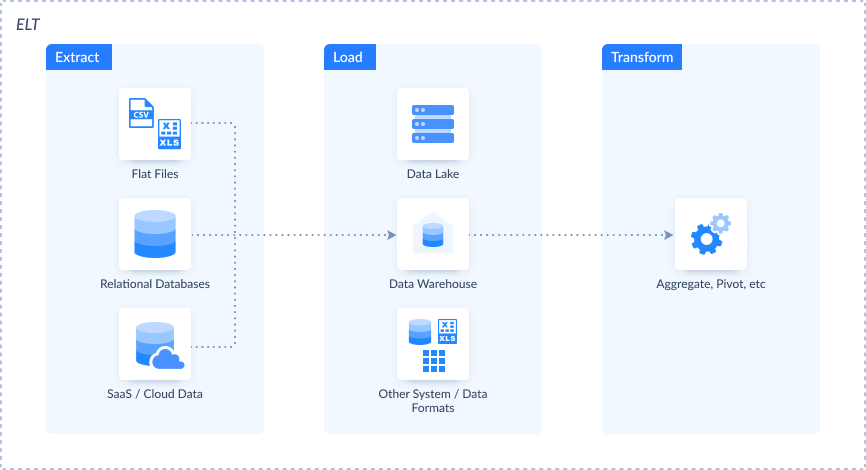
| ETL | ELT | |
|---|---|---|
| Overview | Emphasizes extracting, transforming, and then loading data into a target repository. | Focuses on extracting data, loading it into the target first, and then performing transformations. |
| Use Case | ETL suits scenarios where data requires significant transformation before storage. | ELT is optimal when raw data can be directly loaded into the target and transformed later. |
| Pros | Cleaner data that is better for data analysis. | Fast loading of raw data, well-suited for cloud-based data warehouses. |
| Cons | A bit difficult to maintain than ELT pipelines. | May lead to a cluttered data store and unclean data. |
ETL vs. Data Virtualization
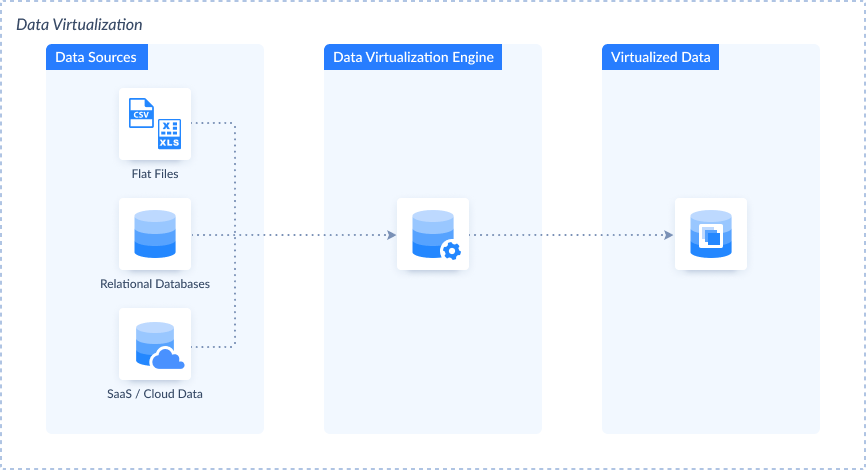
| ETL | Data Virtualization | |
|---|---|---|
| Overview | Physically moves and transforms data into a centralized repository. | Provides a virtual layer to access and manipulate data without physically moving it. |
| Use Case | ETL is good for creating a consolidated data store. | Data virtualization suits scenarios where real-time access to disparate data is critical. |
| Pros | Centralizes data for comprehensive analysis. | Enables real-time access without moving data physically. |
| Cons | Involves data movement, potentially leading to latency. | May face performance challenges with large datasets. |
ETL vs. Stream Data Integration (SDI)
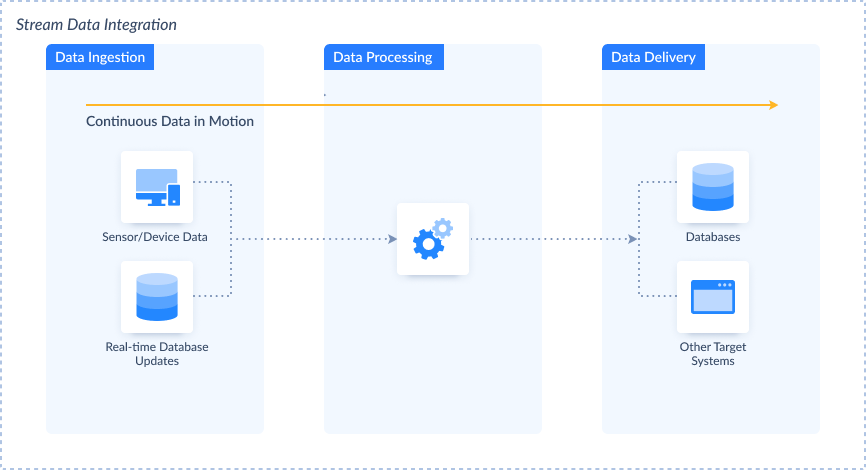
| ETL | Stream Data Integration | |
|---|---|---|
| Overview | Processes data in batches, suitable for periodic updates. | Handles data in real-time (data in motion), enabling instant analysis and decision-making. |
| Use Case | ETL is apt for scenarios where real-time processing is not critical. | SDI is essential for immediate insights and actions. |
| Pros | Suitable for scenarios where data updates at regular intervals. | Provides real-time insights and actions. |
| Cons | May not provide real-time insights for time-sensitive scenarios. | Complexity increases in managing continuous data streams. |
So, each data integration method comes with distinct advantages and challenges. It influences the choice based on specific business requirements.
What are Traditional and Modern ETL?
ETL processes have undergone a transformative journey. It evolved from traditional to modern approaches.
Traditional ETL
- Overview:
- Traditional ETL involves the sequential extraction, transformation, and loading. This often runs in batch processes.
- Characteristics:
-
- On-premises, with fixed infrastructure.
- Batch processing, suited for large volumes of data.
- Rigid and linear workflow, with limited scalability.
- Use Case:
- Traditional ETL is good for businesses with stable, predictable data volumes and processing needs.
- Pros:
- Established, reliable, and suitable for consistent data processing.
- Cons:
- Limited scalability, may struggle with real-time data requirements.
Modern ETL and ETL in the Cloud
- Overview:
- Modern ETL embraces cloud-based solutions, introducing flexibility, scalability, and real-time processing capabilities.
- Characteristics:
-
- Cloud-based infrastructure, providing scalability and cost-effectiveness.
- Emphasis on real-time or near-real-time data processing.
- Modular and flexible architecture to accommodate diverse data sources.
- Use Case:
- Modern ETL is good for businesses with fluctuating data volumes. It also suits agile businesses needing real-time insights.
- Pros:
- Scalable, adaptable to changing data landscapes, and capable of real-time processing.
- Cons:
- Potential reliance on cloud services, requiring a robust internet connection.
So, the shift from traditional to modern ETL reflects the evolving demands. Traditional ETL provides stability and reliability. But modern ETL brings agility, scalability, and real-time capabilities. Modern ETL also meets the challenges of today's dynamic data environments in the cloud.
What are the Challenges Associated with ETL?
ETL processes encounter several challenges that can impact efficiency and effectiveness. Acknowledging and addressing these challenges is crucial for optimizing ETL workflows.
Data Quality
- Challenge:
- Ensuring data accuracy and consistency across diverse sources can be challenging.
- Impact:
- Poor data quality can lead to inaccurate analyses and decision-making.
- Mitigation:
- Use effective data validation checks and cleaning routines during the transformation process.
Scalability and Performance
- Challenge:
- As data volumes grow, ETL processes may face scalability and performance issues.
- Impact:
- Slower processing times, increased resource use, and potential bottlenecks.
- Mitigation:
- Optimize queries, use parallel processing, and consider distributed processing frameworks.
Debugging
- Challenge:
- Identifying and resolving errors within complex ETL workflows can be time-consuming.
- Impact:
- Delays in data processing and potential inaccuracies in the transformed data.
- Mitigation:
- Use comprehensive logging and monitoring, adopt debugging tools, and conduct thorough testing.
Challenges in the Cloud
Cloud-based ETL faces issues related to data volume, pricing models, and usability.
- Volume and Pricing:
-
- Challenge: Cloud providers often charge based on data volume that may lead to cost concerns.
- Impact: Increased costs and potential data transfer bottlenecks.
- Mitigation: Optimize data storage and transfer strategies. Carefully evaluate pricing models. And choose user-friendly cloud ETL tools.
- Usability:
-
- Challenge: Cloud ETL tools may have a learning curve and need to adapt to new interfaces.
- Impact: Slow implementation of ETL processes.
- Mitigation: Provide adequate training, documentation, and support for users transitioning to cloud-based ETL.
Learning Curve in the Chosen ETL Tool
- Challenge:
- Users may face challenges in mastering the selected ETL tool.
- Impact:
- Slow adoption, potential errors, and inefficiencies in the ETL process.
- Mitigation:
- Comprehensive training, documentation, and continuous support. Users need these to navigate the chosen tool effectively.
So, addressing these challenges helps in the ETL process efficiency and reliability. Using proactive measures and adopting best practices can mitigate these challenges.
What are the Best Practices in ETL
To optimize ETL processes and overcome challenges, adopting best practices is important. These practices contribute to the success of ETL workflows.
Data Quality Assurance
- Best Practice:
- Use thorough data validation checks during the transformation process.
- Why:
- Ensures accuracy and consistency, preventing errors in downstream analyses.
Performance Optimization
- Best Practice:
- Optimize queries, use parallel processing, and consider distributed processing frameworks.
- Why:
- Enhances processing speed, resource use, and scalability.
Logging and Monitoring
- Best Practice:
- Put comprehensive logging and monitoring mechanisms in place.
- Why:
- Facilitates timely identification and resolution of errors, ensuring data integrity.
Testing
- Best Practice:
- Conduct thorough testing of ETL workflows in a separate environment.
- Why:
- Identifies and rectifies potential issues before deployment, reducing the risk of inaccuracies.
Cloud-specific Best Practices
- Optimizing Data Volume and Pricing:
-
- Best Practice: Load only what is needed from your user requirements. If possible, use data compression techniques and efficient storage strategies.
- Why: Mitigates costs associated with cloud-based ETL by optimizing data transfer and storage.
- Usability:
-
- Best Practice: Provide adequate training, documentation, and support for users.
- Why: Reduces the learning curve, ensuring smooth adoption of cloud ETL tools.
Version Control
- Best Practice:
- Use version control for ETL workflows and scripts.
- Why:
- Facilitates tracking changes, rollback options, and collaboration among team members.
Error Handling
- Best Practice:
- Establish robust error-handling mechanisms.
- Why:
- Ensures graceful handling of errors, preventing data inconsistencies and interruptions.
Incremental Loading
- Best Practice:
- Use incremental loading instead of full loading. This ensures processing only changed or new data.
- Why:
- Enhances processing efficiency, particularly in scenarios with large datasets.
Documentation
- Best Practice:
- Maintain comprehensive documentation for ETL processes and workflows.
- Why:
- Facilitates knowledge transfer, troubleshooting, and future enhancements.
So, using these best practices in ETL processes reliable and scalable data integration.
Steps in a Successful ETL Project
- 1. Gather User Requirements
- Define project goals, data sources, and user expectations. Aligning user requirements with ETL goals ensures the project's relevance and success. Remember that users will not provide the sources and destinations for you. But they will provide the end result they want.
- 2. Study and Analyze Existing Data Sources
- Check the characteristics, formats, and quality of existing data sources. This step aids in designing transformations. This also helps in addressing potential data quality issues. Always align it with best practices in data quality assurance.
- 3. Analyze Target Repository
- Understand the structure and requirements of the target repository. This analysis guides the design of the ETL process, especially in transformation. This will ensure compatibility and efficiency, adhering to best practices in performance optimization.
- 4. Define Transformations Needed to Map Data from Source to Target
- Define transformations based on user requirements and data source characteristics. This step ensures accurate mapping, aligning with best practices in data quality assurance.
- 5. Design and Create the ETL Pipeline Using Your Chosen ETL Tool
- Use the insights gained to design and create the ETL pipeline. Choose an ETL tool that fits with project requirements. The tool should align with best practices in performance optimization and usability.
- 6. Test the Pipeline
- Conduct thorough testing of the ETL pipeline with a copy of real data from production. Identify and rectify any issues. Follow the best practices in testing to ensure the reliability and accuracy of the process.
- 7. Deploy the Pipeline
- Deploy the tested ETL pipeline to the production environment. This step involves using version control to deploy the pipeline.
- 8. Monitor
- Track the performance of the pipeline and identify any anomalies. Nothing is perfect at first. Continuous monitoring aligns with best practices in logging and monitoring. It facilitates error identification and resolution.
These steps contribute to the success of an ETL project while adhering to best practices.
How to Learn ETL for Beginners
- 1. Know the Basic Concepts of ETL:
- Familiarize yourself with the fundamental concepts of ETL. Understanding the core principles sets the foundation for effective learning.
- 2. Start with an Easy-to-Use GUI Tool. No Programming is Required:
- Begin your ETL journey with user-friendly GUI (Graphical User Interface) tools. These tools provide a visual approach to ETL. So, it allows beginners to grasp concepts without diving into coding complexities.
- 3. Start with Basic Data Sources like CSV and Excel:
- Practice ETL processes with simple data sources such as CSV files or Excel spreadsheets. Working with straightforward datasets helps build confidence. It contributes to a solid understanding of the extraction and transformation processes.
- 4. Pick an Easy Data Integration Scenario and Advance on Your Own Pace:
- Progress to more complex data integration scenarios as you become comfortable with the basics. Gradually advancing allows for a steady learning curve and deeper comprehension.
- 5. Advance to Cloud Data Sources and Targets:
- Explore ETL processes involving cloud-based data sources and targets. Acquiring skills in cloud-based ETL aligns with modern practices and industry trends.
These steps provide a structured approach for beginners to learn ETL. It starts from basic concepts and gradually advances to more complex scenarios. Try a hands-on practice with user-friendly tools and diverse data sources. It will enhance the learning experience.
Tips for Choosing an ETL Tool
Selecting the right ETL tool is pivotal for successful data integration. Consider the following tips to make an informed decision:
- 1. Compatibility and Integration:
- Choose an ETL tool that seamlessly integrates with your existing data sources. Compatibility ensures a smooth workflow without disruptions.
- 2. Scalability and Performance:
- Prioritize tools that offer scalability to accommodate growing data volumes. Opt for ETL solutions with efficient performance capabilities to handle large datasets effectively.
- 3. Ease of Use and Learning Curve:
- Check the tool's user interface and the learning curve it presents. Opt for tools with an intuitive design and comprehensive documentation. This will ease quick adoption by your team.
- 4. Flexibility and Customization:
- Look for ETL tools that provide flexibility in designing and customizing workflows. This ensures adaptability to changing business requirements and data structures.
- 5. Data Security and Compliance:
- Ensure that the chosen ETL tool adheres to industry standards for data security and compliance. This is especially crucial when handling sensitive or regulated data.
- 6. Community Support and Vendor Reputation:
- Check for a strong community and vendor support. A robust community ensures a wealth of resources for problem-solving. Meanwhile, a reputable vendor signifies reliability and continuous improvement.
- 7. Cost Considerations:
- Check the total cost of ownership. Consider not only the initial fees but also ongoing maintenance and potential scalability costs. Ensure that the investment aligns with the organization's budget and long-term goals.
- 8. Connectivity to Data Destinations:
- Confirm that the ETL tool supports various data destinations you need. These include databases, cloud services, and analytics platforms. A tool with diverse connectivity options ensures flexibility in data delivery.
Real-World Examples of ETL in Action
See how modern companies have used ETL to improve their operations and efficiency.
-
Technevalue enhances Telco network performance with a data-driven approach. They used ETL to gather data from different devices into a data warehouse. Then, from the data warehouse comes analytical reports. See their success story here.
-
Cirrus Insights used ETL to enhance and automate day-to-day data-related tasks. The goal was to stop spending too much time and money on complex integrations. They integrated various data sources from different systems into Salesforce. See their ETL story here.
-
Another successful data warehouse project with ETL was done in a company called Convene. See how they integrated various data sources into the Amazon Redshift data warehouse here.

Future Trends in ETL
ETL is evolving in response to emerging technologies and changing data demands. Several trends are shaping the future of ETL:
- 1. Real-time and Streaming ETL:
- The demand for immediate insights continues to rise. It drives a shift towards real-time and streaming ETL processes. This trend caters to the need for instant data analysis and decision-making.
- 2. Machine Learning Integration:
- Integrating Machine learning into ETL workflows continues to increase. It automates data transformations and enhances predictive analytics. This trend streamlines processes and opens avenues for more advanced data analysis.
- 3. Serverless ETL:
- Serverless computing continues to gain traction in ETL. It allows organizations to run ETL processes without managing the underlying infrastructure. This trend enhances scalability, reduces operational overhead, and promotes cost-efficiency.
- 4. Data Catalogs and Metadata Management:
- The emphasis on data governance is driving the adoption of data catalogs and robust metadata management in ETL. These tools streamline data discovery. It also enhances lineage tracking and ensure compliance with data regulations.
- 5. Cloud-Native ETL:
- ETL processes are increasingly becoming native to cloud environments. This trend leverages the scalability, flexibility, and cost-effectiveness of cloud platforms.
- 6. Low-code/No-code ETL:
- The rise of low-code and no-code development platforms extends to ETL. It allows users with minimal coding skills to design ETL workflows. This democratization of ETL enhances accessibility and accelerates deployment.
These trends collectively signify a future for ETL. This future ETL is agile, intelligent, and aligned with the evolving needs of organizations. Embracing these advancements ensures that ETL processes remain at the forefront of efficient and innovative data management.
Conclusion
Mastering ETL processes is integral to effective data management in today's dynamic landscape. ETL continues to evolve from its historical roots. With ETL, organizations can unlock the power of data for informed decision-making.
As we navigate the data-driven future, the importance of ETL remains paramount. Whether you are a beginner or not, the journey involves understanding core concepts and adopting best practices. ETL is not just a process. It's a strategic enabler, propelling organizations towards agility, efficiency, and innovation. Embrace the transformative potential of ETL. Empower your organization to harness the full value of its data assets.