Articles • by Edwin Sanchez • March 05, 2024
A data pipeline is a process that takes raw data from different sources and transfers it to a data storage system where it can be analyzed further. Raw data can come from various sources with different formats. It may pass through some transformation, like aggregation, filtering, and pivoting. These transformed data need to align with the destination. Hence, data mapping will take place. Then, the final destination will be ready for its intended purpose. This can be another system, a data warehouse, or a data lake.
Data pipelines are the vital conduits in our digital infrastructure. It ensures there is timely data to analyze and learn, so decisions are data-driven.
The result of any data pipeline is an input to further analysis, reports, or another system. Think of data science projects and business intelligence dashboards as examples. Data prepared for these projects will propel sales, marketing, and more.
The illustration below gives an idea of what data pipelines are.
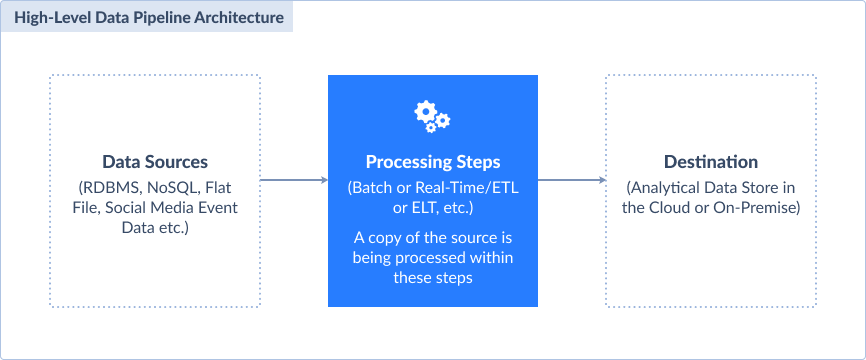
These processes are hidden from most people. But they carry and transform the vital information that fuels our innovation.
This article serves as a guide through the intricacies of data pipelines. This will delve into their evolution and explore the mechanics that make them work. We will also uncover the key features that elevate them to indispensable tools.
Let's begin.
The Evolution of Data Pipelines
Data pipelines have undergone a significant technological transformation. Initially, data was moved in batches on a defined schedule. This was reliable but not swift. Data cleansing and further transformation occurred before it reaches the destination. Large amounts of datasets meant hours of batch processing.
As compute resources improve, data pipelines are no longer limited to a fixed schedule done in batches. Now, the process is more dynamic and fueled by real-time demands. The processed data reaches its destination in almost an instant. Data pipelines also involve processes running in parallel to each other.
The need of such transition is clear in industries where milliseconds can make all the difference, like healthcare and finance. As many decision-makers want more instant insights, more and more of these streaming pipelines will replace many, if not all, batch processes.

How Does a Data Pipeline Work?
Data pipelines process and transform data as it moves from source to destination. Information passes from one stage to the next. At times, it needs a staging area for all the disparate data sources before cleansing and other transformations occur. But sometimes, it only involves extraction and loading. There is either minimal transformation or transformation will happen after loading.
Data Pipeline Components
A data pipeline works by using all or most of these components:
-
Data sources: These can be flat files, SQL and NoSQL databases, or data from a cloud service. Data pipeline tools may cover dozens or even hundreds of sources they call connectors to open and process information from them.
-
Transformations: These are portions of the process that will reshape data to become useful for storage and analysis. It can be as simple as converting date to text or breaking a whole line of text into different pieces of information. It can also be as complex as extracting texts from images or summarizing a large dataset.
-
Dependencies: Sometimes, a data pipeline will only continue if a certain condition is met. For example, it waits for a CSV file to exist in an FTP location before the pipeline proceeds. Or a manual verification happens before moving on to the next stage. In any case, the data pipeline is put in a waiting state until a dependency is met.
-
Data repositories: Data passes through until it reaches the destination where processed data is stored. Data warehouses and data lakes are typical examples of these.
Data pipelines use frameworks to propel the data relay forward. It's the technology that powers these pipelines. They provide the infrastructure, the patterns, and more. All to ensure a smooth and efficient process. Furthermore, it allows data experts to reuse the success of these frameworks on other data science projects.
As we delve into these mechanics, notice that data pipelines are not rigid structures. They adapt to the changing data landscape. This flexibility ensures they can handle diverse data types and evolving requirements.
Benefits of Implementing Data Pipelines
Data pipelines are not only a means to put various data sources into one format. The bigger picture points to more benefits as seen below:
-
Efficiency Gains: Streamlined data movement and transformation reduce processing time, boosting overall operational efficiency. Reducing the steps through automation is a very welcome feature coming from a manual process.
-
Real-Time Decision-Making: Swift processing enables organizations to make informed decisions in real-time. It lets them stay ahead of the curve. For example, a sales dashboard that updates as sales occur will help monitor sales targets. The sales team can adjust quickly if things don't happen as planned.
-
Data Accuracy Improvement: Automated processes and validation steps enhance data accuracy, minimizing errors and discrepancies.
-
Cost Reduction: Efficient use of resources and optimized workflows result in cost savings. Taking away manual work either removes or cuts costs.
-
Scalability and Flexibility: Scalable designs accommodate growing data volumes, ensuring pipelines remain flexible in dynamic environments. A scalable data pipeline also contributes to a scalable business.
-
Enhanced Data Security: Robust monitoring and compliance measures fortify data security. It safeguards against potential breaches and unauthorized access.
-
Collaboration Facilitation: Clear documentation and standardized processes promote collaboration among teams. It fosters a cohesive working environment.
-
Increased Data Availability: Continuous monitoring and maintenance ensure data availability. It reduces downtime and optimizes accessibility for users.
Implementing data pipelines is not only a technological upgrade. It is a strategic move that reaps a multitude of benefits. These pipelines make data processing dynamic and value-driven. It becomes a pivotal force in shaping a resilient and data-centric future.
Key Features of a Modern Data Pipeline
Modern data pipelines boast key features that transform them into technological pillars. These features redefine the data landscape. It provides a dynamic and efficient framework for information flow.
Real-time data processing is the first spotlight. This feature ensures that insights are fresh. All to cater to the demands of our fast-paced digital age.
Automated data integration takes the stage next. Automation streamlines the entire process, reducing manual intervention and potential errors. Data pipeline tools allow data experts to schedule when a data pipeline begins and how many times it has to occur.
Enhanced data security and compliance is an essential but sometimes forgotten feature. It ensures data integrity and compliance with regulations. It also makes private information remain a secret through data encryption and other security means.
These key features collectively propel modern data pipelines into a league of their own. It adapts to the evolving needs of our data-hungry world. It ensures someone's data is safe as it passes along different stages in the data pipeline.
Types of Data Pipelines
Data pipelines come in diverse types. Each type has pros and cons. Choose from these types as they apply to a certain business case.
Batch vs Real-Time
We can categorize data pipelines by how much data they process or how fast they move.
First up, we have batch pipelines. This method is reliable but lacks the immediacy required for real-time decision-making. If products are slow-moving, like expensive cars, the business owner may opt for a weekly or monthly batch process for sales reports.
In contrast, real-time pipelines process data as they come. They cater to the demands of industries where timely insights are non-negotiable. A service like Netflix benefits from real-time data pipelines. It helps track service status and lessen downtimes.
However, more recent batch solutions can be scheduled to process data much more often, while using smaller batches. The interval between pipeline runs in such solutions can be measured in minutes, not in days or hours, and this provides near-real-time speed.
ETL vs ELT vs Reverse ETL
We can also categorize data pipelines on the steps undertaken to take raw data to its destination.
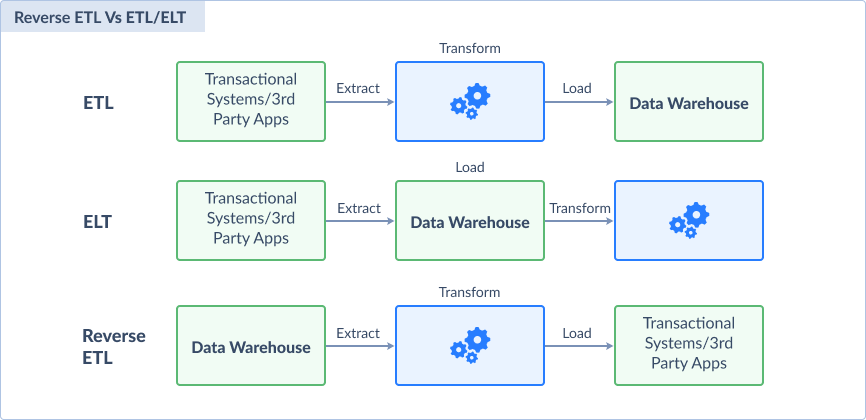
First are ETL pipelines—Extract, Transform, Load. These pipelines pull data from various sources, transforming it into a cohesive format, and loading it into a destination. This usually happens in batches of data. But nothing is stopping a data integration expert from extracting data as they come. Then, transform it and load it to the target repository. The process can also run one-time or recurring in a fixed schedule. Note that data pipeline is a broader term and is not interchangeable with the term ETL.
ELT pipelines, on the other hand, put the transformation as the last step—Extract, Load, Transform. This approach is ideal for scenarios where applying transformation needs to be flexible. Unlike ETL, adding and changing transformations is less invasive to the pipeline.
Finally, reverse ETL is also ETL but data warehouses become the sources instead of targets. Data warehouses become data silos themselves when users feel it is another step in their daily workflow. But, it can increase their productivity if the insights within it are pushed back to the apps they use daily. This is where reverse ETL comes into play. For example, reverse ETL can push back customer insights from a data warehouse to Salesforce. Then, business teams become better equipped to deal with clients with enriched client information.
The differences of each are shown below. Note how the different data pipeline components fit in each of the steps.
Data Pipeline Frameworks
A data pipeline framework provides the structure and functionality to move data from source to destination. Developers can choose between using code, a graphical user interface, or a mix of both.
Within this realm, frameworks can be broadly categorized as open-source or proprietary.
Open-source frameworks are community-driven, offering flexibility and transparency. Notable examples are Apache Airflow and Apache NiFi.
Apache Airflow orchestrates workflows with code, ensuring efficient task management in data pipelines. Apache NiFi, on the other hand, provides a visual interface for seamless information flow.
In contrast, proprietary frameworks are developed and owned by organizations. They are often bundled with commercial data pipeline tools.
Microsoft's SSIS offers a comprehensive platform for data integration and transformation. Skyvia is a cloud-based data platform service. It simplifies data loading, backup, and synchronization through a graphical interface. Others in this space include Informatica, Hevodata, Azure Data Factory, and more.
These proprietary frameworks set the stage for commercial data pipeline tools. Each of them follows a unique approach. Choosing a data pipeline tool depends on how well the framework will fit the needs of the users and their organizations.
Challenges in Building and Maintaining Data Pipelines
Building and maintaining data pipelines is not always smooth sailing. Challenges abound in this complex digital landscape. Below are the common challenges experts face in building and maintaining data pipelines:
-
Complex Data Sources: Varied formats and structures may create a tangled web of information. That's why data pipeline tools need to have an updated list of connectors.
-
Data Quality Issues: Inaccuracies or inconsistencies in the input can ripple through the entire pipeline. These can affect outcomes.
-
Scalability Concerns: This is a critical concern. As data volumes grow, pipelines must adapt. This will prevent bottlenecks and ensure optimal performance.
-
Human Error Risks: This is an ever-looming threat. Misconfigurations or oversights can disrupt the entire pipeline. So, the need for rigorous testing.
-
Monitoring and Maintenance Needs: The need for constant monitoring and maintenance is evident. Regular check-ups are crucial to catch and address issues before they snowball.
Any software requires careful attention. By addressing these challenges, it will enhance the health of data pipelines.
Best Practices for Effective Data Pipelines
Navigating the intricacies of data pipelines demands adherence to best practices. Reduce the challenges by following the list below:
- 1. Clear Documentation:
- Ensure clarity: Document every aspect, from data sources to transformations, fostering understanding and collaboration.
- 2. Robust Testing Procedures:
- Ensure reliability: Rigorous testing catches errors early, preventing disruptions in the data flow.
- 3. Scalable Design:
- Ensure adaptability: Design pipelines with scalability in mind, accommodating growing data volumes seamlessly.
- 4. Defensive Design:
- Ensure errors are handled properly: From connection problems to a changed API to wrong user input, errors can stop your pipelines anytime. Proper error handling ensures processed data are rolled back to its initial state. The right people should also be informed to fix the problem.
- 5. Monitoring Systems:
- Ensure health: Use robust monitoring systems to catch issues and ensure the continuous flow of data.
- 6. Regular Maintenance:
- Ensure longevity: Scheduled maintenance keeps pipelines healthy, addressing potential bottlenecks before they escalate.
Case Studies and Examples
Companies leveraging data pipelines gain by reducing manual work and getting analytics done on time. Let us have some of these companies who did succeed in their data journey through data pipelines.
-
NISO, an outsourced CFO company, provides services to the merchant cash advance industry. Their challenge is to integrate operational systems that use MySQL and QuickBooks Online. See their successful journey in using data pipelines here.
-
Teesing is a company developing and assembling turnkey systems for the control of gases and liquids. Their challenge is the manual work of exporting website data to CSV. Then, they need to import the CSV to their CRM. What they need is a seamless solution that will make these tasks automatic. Their success story is accessible here.
-
Plüm Énergie is a green electricity supplier, aiming to reduce the share of gray energies in France. They wanted to automate their PostgreSQL with business data to Jira. Initially, it was done manually. See how they became productive in their success story here.
-
A4 International is a registered Salesforce consulting partner with many clients in various industries. One of their challenges includes a real-time integration of a SQL Server database and Salesforce. See their interesting solution here.
Data pipelines have been around for years, and these companies are not the only ones to enjoy the benefits. But knowing these remarkable case studies increases your confidence on your own data pipelines.

Choosing the Right Data Pipeline Solution for Your Business
Choosing the right data pipeline tool is not a simple walk in the park. You need to consider different factors before finally making the decision. Here they are:
- 1. Compatibility with Data Sources:
- Ensure integration: Check if the tool supports various data sources to ensure compatibility. Different tools have connectors to these data sources. Make sure the tool has the needed connector.
- 2. Ease of Use and Learning Curve:
- Focus on usability: Opt for tools with an intuitive interface and a manageable learning curve.
- 3. Scalability:
- Plan for growth: Choose a tool that scales seamlessly with your data processing needs.
- 4. Community and Support:
- Ensure help is available: Check the tool's community and support options for help when needed.
- 5. Security Features:
- Focus on protection: Assess the security features to safeguard sensitive data throughout the pipeline.
- 6. Cost Considerations:
- Budget wisely: Analyze the pricing model to ensure it aligns with your organization's budget.
- 7. Flexibility and Customization:
- Meet specific needs: Opt for a tool that allows customization to address unique data processing requirements.
- 8. Monitoring and Logging Capabilities:
- Ensure visibility: Choose a tool with robust monitoring and logging features for continuous visibility.
Choosing a data pipeline tool involves a careful balance. Technical specifications are not everything. Usability and strategic alignment also matter. Each factor plays a crucial role in meeting current needs. It should also align with the organization's future growth and data processing objectives.
Conclusion
It is crucial to know that data pipelines and tools are not an insurmountable challenge. With the right knowledge, user-friendly tools, and determination, mastering data pipelines is achievable. It is a dynamic realm where efficiency and innovation converge. It will empower organizations to harness the full potential of their data.
So, whether you are a seasoned one or a newcomer to the field, embrace the learning journey. Data pipelines are not only conduits for information. They are the architects of a data-driven future. Dive in, explore, and unlock the immense possibilities that data pipelines offer.