Articles • by Edwin Sanchez • December 31, 2024
The global market for data lakes in 2024 is USD 20.1 billion. With a CAGR of 20.5%, it will grow to USD 74.15 billion by 2031. Meanwhile, the data warehousing market is projected to reach USD 59.05 billion by 2028. The numbers tell the importance of both technologies. This article will provide a detailed guide to compare a data lake vs. a data warehouse.
Choosing which one works best for an organization eludes many. Knowing their key features and use cases with examples will help many understand these amazing technologies.
What is a Data Lake?
Uncovering the differences between a data lake and a data warehouse starts by digging into the details of each. Let’s start with the data lake.
A data lake is a centralized repository designed to store large volumes of raw data in its native format. It supports a variety of data types including:
- Structured data: This is data with well-defined schemas. They are readable by both humans and computers with their spreadsheet-like appearance. Examples: Parquet, Excel files, and database tables.
- Semi-structured data: This is data organized with tags or markers. Examples: XML, JSON.
- Unstructured data: This includes videos, images, and documents.
Below is a diagram of a data lake following the three data types above:
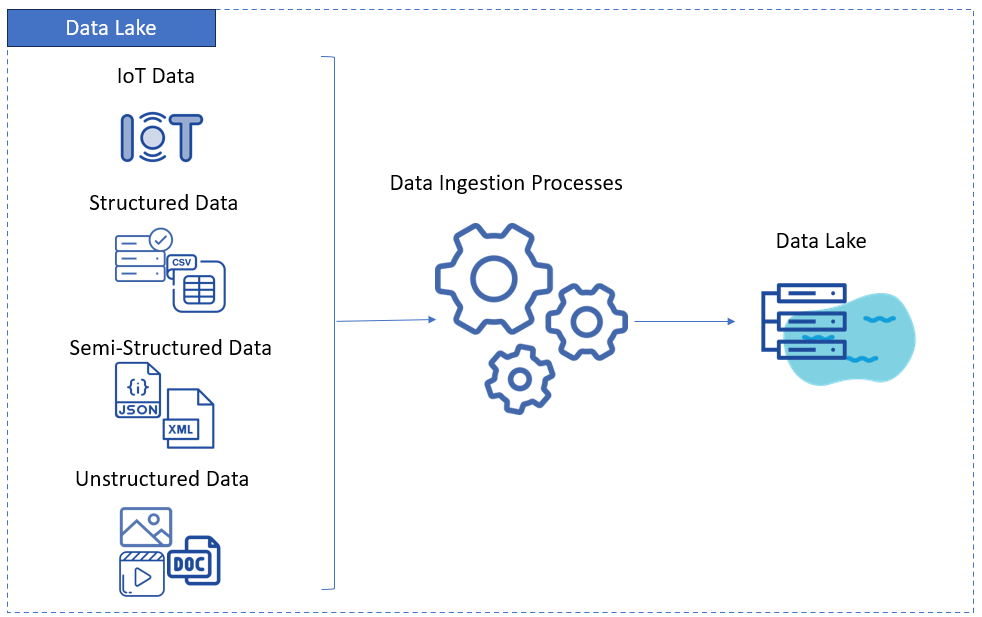
Data lakes do not follow a strict structure or schema when storing data. They are good candidates for staging areas where data is consolidated in their raw formats. Structure is defined when reading data, not when writing data. This is known as schema-on-read.
Data lakes also use a flat architecture where data is hierarchical or non-relational when stored. Using folders and subfolders makes up the hierarchical organization of files.
Data scientists and engineers are the primary users of data lakes. They uncover insights from raw data. Examples of known data lakes they use are Azure Data Lake and AWS S3.
Challenges in maintaining a data lake include the risk of becoming data swamps, data governance issues, and query complexity.
Key Features of Data Lakes
Key features of a data lake differentiate it vs. a data warehouse. Check them out below:
- Data Storage Flexibility: Data lakes are flexible because they store not only structured data but also semi-structured and unstructured data. Storage of these files does not need predefined schemas.
- Scalability: Data lakes can scale horizontally to accommodate massive data volumes.
- Low-Cost Storage: Compared to traditional data warehouses, data lakes provide cost-effective storage for large datasets due to their flat architecture and use of cloud-based services.
- Schema-on-Read: Data is stored as-is and structured only when accessed. This allows flexible data exploration and analytics.
- Data Security and Governance: Modern data lakes offer data encryption, access control, and governance frameworks.
- Support for Advanced Analytics: Data lakes enable Artificial Intelligence (AI), ML, and big data analytics. They leverage tools like Hadoop, Databricks, and AWS Glue.
- Real-Time and Batch Processing: Data lakes support both real-time streaming and batch data ingestion pipelines.
Use Cases of Data Lakes
Use cases of a data lake also differentiate it from a data warehouse. The following are some of them:
- Big Data Analytics: Data lakes store large volumes of raw data, making them ideal for big data analytics. Companies use them to derive insights from structured and unstructured data (e.g., logs, sensor data) across industries like finance, healthcare, and retail.
- Machine Learning: Data lakes support machine learning models by storing raw datasets. These include images, texts, and videos. Training algorithms use these to improve ML accuracy.
- IoT Data Storage: IoT systems generate massive volumes of sensor data in various formats. Data lakes handle this unstructured data to enable analysis of real-time and historical data. This will then be used for predictive maintenance, optimization, and operational intelligence.
- Advanced Reporting and BI: Data lakes aggregate raw data from multiple sources. It provides a unified data store for data warehouses to process these raw data for analysis.
- Data Archiving: Data lakes can also be used for long-term storage of raw data. This is a low-cost storage for archiving large datasets. It also maintains access to this archive for future analysis or regulatory requirements.
Data Lake Advantages
See the list of data lakes pros below:
- Scalability: Data lakes can handle massive volumes of diverse data types with high scalability. This makes them ideal for big data applications.
- Cost-Effective Storage: Compared to traditional databases, data lakes offer lower-cost storage solutions for large amounts of data. This is evident particularly when using cloud-based options.
- Flexibility: Data lakes allow organizations to use unprocessed data for a variety of purposes. This includes machine learning, analytics, and real-time data processing.
- Advanced Analytics: They enable advanced analytics, such as predictive modeling and machine learning. By storing data in raw formats, data scientists and engineers can easily work with them to uncover insights.
Data Lake Disadvantages
See the challenges that data lakes can face below:
- Data Swamp Risk: Without proper governance, data lakes can become “data swamps”. Data files are plenty but disorganized and unclean, making it difficult to retrieve meaningful insights.
- Complexity in Data Retrieval: Accessing and querying unstructured data is more complex compared to structured data in a data warehouse.
- Lack of Real-Time Analytics: Data lakes may not be suitable for real-time processing without additional tools or frameworks like Spark or Kafka.
- Data Governance Challenges: Managing data quality and ensuring security can be difficult due to the vast variety of data stored.

What is a Data Warehouse?
A data warehouse is a centralized repository designed to store structured data from various sources.
Data warehouses facilitate analytical reporting and business intelligence. It uses a pre-defined schema or format like a star schema. So, storing data needs to conform to a format before it can persist in a data warehouse. This is known as schema-on-write.
Data warehouses use tables to organize data. There are columns that define properties of an information and rows to itemized them. Data should fit these tables or data will not be written.
Business users and business analysts typically use data warehouses through dashboards and reports. Business Intelligence tools make this easy for them by visualizing data to uncover insights.
Examples of data warehouses in the cloud are Snowflake, Amazon Redshift, and Google BigQuery.
Challenges in maintaining a data warehouse include long implementation times, rigid data structure, and complex ongoing maintenance.
Below is a diagram of how various data flows into a data warehouse: 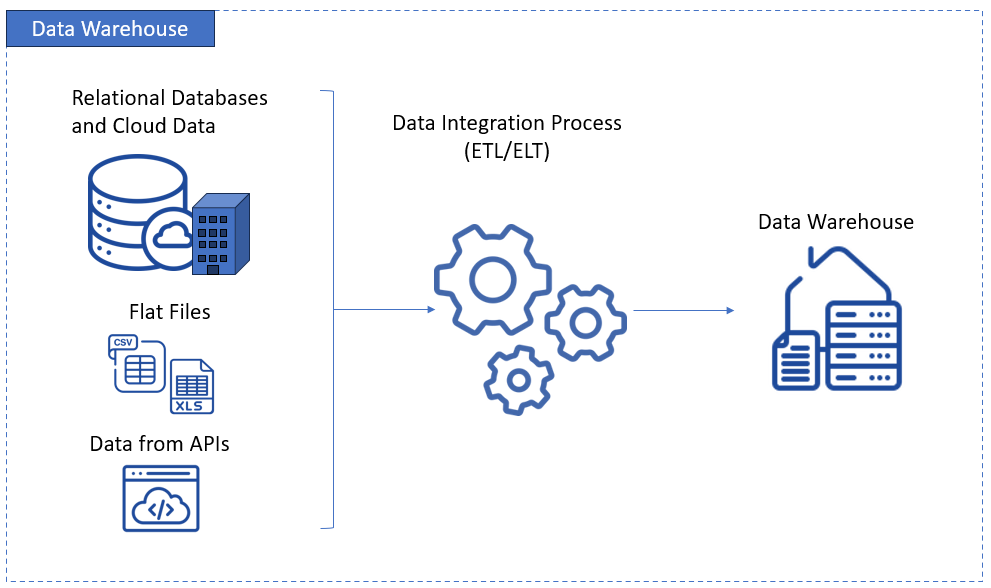
Key Features of a Data Warehouse
Data warehouses are characterized based on the following features:
- Structured Data Storage: Data warehouses store structured data using predefined schemas. The structure organizes data and makes information consistent and easily accessible. Note, however, that Enterprise Data Warehouses also support semi-structured and unstructured data.
- Data Integration: They consolidate data from multiple sources such as transactional databases, cloud systems, and external APIs for comprehensive analysis.
- Schema-on-Write: Data is processed, cleaned, and structured before storage. This makes querying and reporting easier.
- Historical Data Storage: Data warehouses retain historical data, supporting trend analysis and long-term decision-making.
- Optimized for Analytics: Data warehouses can run complex queries and aggregations at high-speed making business intelligence reports easily available.
- Data Consistency and Accuracy: Built-in data validation and ETL (Extract, Transform, Load) processes ensure data accuracy and reliability.
- Real-Time and Batch Processing: They support both real-time and batch data processing for timely insights.
- Data Security and Compliance: The latest encryption, role-based access control, and compliance certifications are features of modern data warehouses.
- Scalability and Performance: Modern cloud-based data warehouses can adapt to growing business needs along with their data.
- Business Intelligence Integration: Data warehouses are friendly to BI tools which makes generating dashboards, reports, and visual analytics seamless.
Use Cases of a Data Warehouse
Below are sample use cases of data warehouses that are common today:
- Business Intelligence and Reporting: With data warehouses, businesses can generate insightful reports and dashboards for data-driven decisions. Examples include sales performance analysis and financial reporting.
- Customer Analytics: Organizations use data warehouses to dig deeper on their customer behavior, preferences, and purchase histories to improve customer service and for personalized marketing.
- Operational Analytics: Data warehouses support monitoring and optimizing daily business operations including inventory management, supply chain tracking, and production efficiency.
- Financial Management and Forecasting: Businesses consolidate financial data into a data warehouse. This will help them manage budgets, forecast revenue, and ensure regulatory compliance.
- Risk Management and Compliance: Data warehouses help identify potential risks, detect fraud, and maintain audit trails for legal and regulatory compliance.
- Healthcare Data Analysis: Healthcare providers use data warehouses to analyze patient records, improve treatment plans, and support medical research.
- Retail and E-commerce Insights: Retailers analyze purchase data, customer demographics, and market trends to optimize inventory, pricing, and promotional campaigns.
- Telecommunications Monitoring: Telecom companies use data warehouses to analyze call records, monitor network performance, and reduce service disruptions.
Data Warehouse Advantages
Data warehouse can be a good choice for the following reasons:
- Data Consolidation: Provides a single source of truth for reporting and analysis.
- High Query Performance: Optimized for complex analytical queries, enabling fast data retrieval of structured data.
- Data Consistency: Ensures consistent data definitions and formats, reducing discrepancies.
- Historical Analysis: Stores historical data for trend analysis and forecasting.
- Enhanced Decision-Making: Supports business intelligence tools for data-driven decisions.
- Data Security and Compliance: Provides secure access and audit trails for compliance purposes.
Data Warehouse Disadvantages
While data warehouse is good for analytical reports, it has its challenges:
- High Initial Costs: Significant investment in hardware, software, and skilled personnel.
- Complex Maintenance: Requires ongoing management, updates, and performance tuning.
- Data Rigidity: Structured data models can limit flexibility when dealing with new data types.
- Long Implementation Time: Deployment can take months or even years.
- Data Latency: Real-time data processing can be challenging without additional tools.
- Data Duplication: Storing large volumes of historical data can increase storage costs.
Data Lake vs. Data Warehouse: Key Differences
The following table is a summary of the data lake vs. data warehouse comparisons:
| Aspect | Data Lake | Data Warehouse |
|---|---|---|
| Purpose | Data exploration, big data analytics | Business intelligence, reporting |
| Data Types/Formats | Raw, unstructured, semi-structured, structured | Structured and processed data only |
| Architecture | Schema-on-read (define schema when querying) | Schema-on-write (define schema during data loading) |
| Use Cases | Machine learning, real-time analytics, IoT data processing | Business reports, dashboards, operational analytics |
| Users | Data scientists, analysts, engineers | Business analysts, executives, business users |
| Storage Costs | Lower (commodity storage) | Higher (premium performance storage) |
| Performance | Depends on tools and configurations | Optimized for fast SQL queries |
| Scalability | Highly scalable for massive datasets | Scalable but more limited by cost |
Key Takeaways:
- Data Lakes excel in storing vast amounts of raw, diverse data for advanced analytics but needs skilled talents to query and manage.
- Data Warehouses are structured, business-ready systems optimized for analytical reporting but come with higher costs and predefined data models.
When to Choose a Data Lake vs. Data Warehouse
The following is further information on when to choose a data lake vs. a data warehouse.
When to Choose a Data Lake
Below are ideal scenarios where data lakes are a good fit:
- Diverse Data Formats: Your data includes raw, unstructured, or semi-structured types like JSON, logs, images, and videos.
- Big Data and Analytics: You need large-scale data storage for Artificial Intelligence, Machine Learning, or real-time analytics.
- Skilled People: When you have data scientists and/or engineers in your team, or someone in your team has the skills to act as one.
- Exploratory Analysis: Data scientists need flexible access to run advanced analytics and build models.
- Cost-Effective Storage: You have a tight storage budget and need scalable, low-cost storage.
- IoT and Streaming Data: You’re handling high-velocity data from connected devices or sensors.
The following are the scenarios where data lake is not ideal:
- When business users need easy-to-use data access for reporting and quick decision-making.
- When querying data quickly with predictable performance is critical.
When to Choose a Data Warehouse:
Below are the ideal situations when data warehouses are good for your data management strategies:
- Structured Data Needs: You work mostly with well-defined, tabular data.
- Business Intelligence (BI): You require fast queries, dashboards, and reports for business teams.
- Data Consistency and Governance: You need strong data governance, accuracy, and compliance.
- Operational Reporting: When real-time reporting for business-critical processes is essential.
Below are the situations when data warehouse is not ideal:
- When dealing with unpredictable, evolving data types.
- When long-term data storage at minimal cost is a priority.
Key Takeaways:
Use Data lakes for raw, large-scale, and exploratory data needs, and you have data scientists/engineers in your team. Choose Data Warehouses for structured, business-ready reporting with high performance.

Hybrid Data Architectures and Solutions
Hybrid Data Architectures combine the best of both data lakes and data warehouses. This allows businesses to store, process, and analyze data in a more flexible, integrated way. The hybrid approach enables organizations to take advantage of the scalability and low-cost storage of data lakes with the structured querying and performance optimization of data warehouses.
A data lakehouse is a prominent example of this hybrid model. It provides the unstructured data flexibility of a data lake while supporting structured queries and fast analytics of a data warehouse. Examples of platforms using a data lakehouse are Azure Databricks and Google BigLake.
The growing trend is to use a unified solution that combines the best of data lakes and data warehouses. Along with this trend is the idea of not being tied to a single cloud provider.
Benefits of a Data Lakehouse
The following are the reasons to consider a hybrid solution like a data lakehouse:
- Unified Architecture: A data lakehouse integrates the scalability and flexibility of data lakes with the performance and structure of data warehouses. This allows managing all data types and formats (structured, semi-structured, and unstructured) in a single platform.
- Improved Query Performance: Through optimized storage and indexing, a lakehouse can handle large-scale data with faster query performance compared to traditional data lakes.
- Cost Efficiency: It offers a balance between cost and performance. A lakehouse combines the cost-effectiveness of a data lake’s storage with the query efficiency of a data warehouse.
- Simplified Data Governance: With its layered architecture, the lakehouse offers better metadata management, data consistency, and governance compared to data lakes.
- Flexibility: It allows data engineers, data scientists, and business analysts to access both raw and processed data for advanced analytics, reporting, and machine learning in one place.
- Real-Time Analytics: A data lakehouse can support real-time data processing, making it more agile than traditional data lakes, especially for operational analytics.
Use Cases of a Data Lakehouse
Below are the use case scenarios for a data lakehouse:
- Big Data Analytics: For organizations needing to analyze huge amounts of data for all types and formats, with faster query times.
- Business Intelligence (BI) Reporting: Good for organizations that need to run business intelligence reports on top of varied datasets.
- Machine Learning: Best for storing large volumes of unstructured and structured data for training machine learning models.
- IoT Data Storage: The ability to handle raw IoT data alongside processed data makes the lakehouse a powerful tool for IoT-driven applications.
- Real-Time Data Processing: Companies with a need for real-time analytics across different data types will benefit from the real-time processing capabilities of a lakehouse.
Conclusion
Understanding a data lake vs. a data warehouse is crucial to modern data management in any organization. Each has its own key features, use cases, and advantages. Your business goals and current data management practices will drive the choice between a data lake and a data warehouse. A hybrid solution like a data lakehouse is another option.
It is best to evaluate current data strategies and consult experts for implementation. Explore modern data platforms and how other companies are applying them to achieve their business goals.