Articles • by Edwin Sanchez • April 22, 2024
Batch processing is a method of periodically collecting data for a fixed period, processing them as a single unit, and storing the results in a format suitable for reports, analyses, or use in another system.
Combining, filtering, computing, sorting, or summarizing data may need a lot of resources. That is why processing often happens during off-peak times of the day. This is the best time when computing resources are available.
Data collection occurs during a fixed period called a batch window. This batch window could be hourly, daily, weekly, or longer. Stakeholders dictate how long a batch window can be.
Processing occurs at the end of the batch window to produce reports, analyses, and other applicable purposes. The result is not very time-sensitive and need not be immediate. Otherwise, stream processing, another data processing method, better suits the job.
Triggering the process may happen in two ways: automated using job schedulers or manually through human intervention.
One common example of this kind of processing is a bi-monthly payroll process. The system collects attendance data, filed leaves, and more in a two-week batch window. Processing proceeds at the end of the batch window to compute gross pay, deductions, and net pay.
Batch processing can be traced back to 1890 in the United States to process census data. Herman Hollerith invented the electric tabulating machine for that purpose. This machine read and summarized stored data from punched cards. Back then, the machine reduced tabulation time compared to counting them by hand. Today, batch processing still improves productivity and organizations use it for various use cases.
What Are the Common Use Cases of Batch Processing?
Various industries use batch processing for many data processing tasks. The following are some of them:
-
Report Generation: This is the most common use case. Examples include processing data for financial statements, sales reports, performance metrics, and more.
-
Data Warehousing: Updating data warehouses from various sources may need batch processing. This is to support analytics and data-driven decisions.
-
Data Integration: This is about extracting data from various sources into a unified format. Source data can be flat files, databases, SaaS apps, and more. One example is gathering attendance records from a biometrics machine for payroll purposes.
-
Data Backup and Archiving: Examples include backups and archives to ensure data integrity, compliance, and disaster recovery.
-
Data Cleansing and Quality Management: Includes cleaning, deduplicating, and more to improve data quality for downstream processing.
-
Batch Updates: Updating records in databases and other applications based on predefined business rules.
-
Large-Scale Data Processing: Examples include doing analytical tasks on large volumes of data for trend analysis, predictive modeling, and machine learning.
-
Billing and Invoicing: Includes processing billing cycles and generating invoices for services rendered.
-
Batch Email Processing: This includes sending bulk emails to many recipients based on various criteria. This happens on schedule to email subscribers. Purposes can be newsletters, sales pitches, and more.
-
E-commerce Order Processing: Processing orders, updating inventory levels, and generating shipping manifests for e-commerce platforms.
What Are the Benefits of Batch Processing?
Processing in bulk is still in use despite the emergence of stream processing. Below are its benefits:
-
Efficiency: Batch processing removes manual tasks and delivers results faster. It is like the US annual census in 1890. That is why organizations can optimize resource usage and cut processing overhead. Even more, it allows bulk processing of large data common today.
-
Scalability: Batch processing frameworks can improve processing capabilities as data volumes grow. This scalability makes batch processing good for processing workloads of varying sizes.
-
Predictability: Batch processing jobs can run at specific schedules, so, the availability of results is predictable. Predictability is important for managing resources, meeting service level agreements (SLAs), and more.
-
Fault Tolerance: Batch processing tools have ways to handle errors and failures. This includes job retries, checkpointing, and fault recovery. It ensures that data processing jobs can recover from failures. Processing will also continue without data loss or disruption.
-
Offline Analytics: Batch processing is good for offline analytics and reporting on historical data. By bulk processing historical data, organizations can generate insights. They can also identify trends and make data-driven decisions based on a view of past data.

How Does Batch Processing Work?
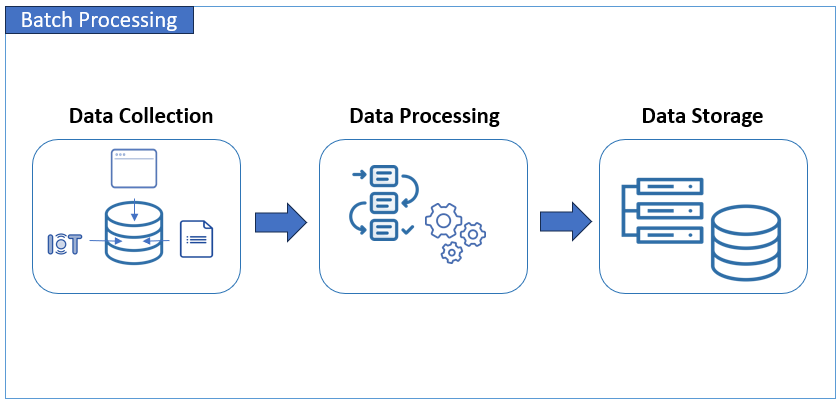
Batch processing works by collecting and processing data in chunks at scheduled intervals. The following is a basic overview of how it works:
-
Data Collection: The process begins with collecting data from various sources. The data may come from user input or device sensors and then saved in databases and files. Data accumulates over time until a predefined period has passed, like a fiscal year or billing period. Then, collected data is grouped to form a batch.
-
Data Processing: The batch of data is then processed based on predefined rules, algorithms, or workflows. This processing may involve data cleaning, aggregation, analysis, or integration with other datasets.
-
Data Storage: After processing, the results are saved in databases, files, or memory cache. These results can help for further analysis, decision-making, or integration with other systems.
-
Scheduling and Automation: Batch processing tools typically have job schedulers. These systems run batch jobs at predefined times without manual intervention. This allows processing even when administrators have gone home or are on vacation.
-
Monitoring and Error Handling: While batch processing is largely automated, monitoring systems are often in place. These monitoring systems track batch job progress, record logs, and detect errors. Error handling mechanisms are recommended to address issues that arise during processing. Possible issues are data validation errors, processing failures, or resource constraints.
What Are the Common Challenges in Batch Processing?
Batch processing, while powerful and useful, also comes with pain points and limitations. Here are some of them:
-
Latency: The data size of the batch introduces latency. This latency may not be suitable for scenarios that need immediate responses. Streaming analytics may be more applicable for immediate results.
-
Data Freshness: Batch processing operates on a batch window. So, there is a delay between data collection and processing times. This delay can impact the freshness of the data, so, it may not be acceptable for scenarios requiring up-to-date information.
-
Complexity: Batch processing workflows can be complex, especially for large-scale and distributed systems. Data experts should design robust data pipelines that can handle dependencies between jobs. Even more, it should address issues on data consistency, fault tolerance, and resource management.
-
Resource Usage: Batch processing jobs often need dedicated computing resources to work efficiently. The larger the data, the higher the memory, processing power, and storage needed. Managing these resources with varying workloads can be challenging.
-
Data Integrity: Ensuring clean data in batch processing can be hard. Distributed data sources and concurrent updates can cause duplicates and other issues. Clean data is important, so batch processing pipelines should address these issues.
-
Scalability: The reality is data will only grow as time passes. So, dealing with this ever-growing data in batch processing is also challenging.
What Are the Best Practices in Batch Processing?
The following batch-processing best practices can address the challenges mentioned earlier:
Optimize Batch Size
Reducing the batch size or batch window can optimize batch processing performance. Smaller chunks can reduce latency. It also improves data freshness, while still maintaining processing efficiency.
Implement Parallel Processing
Parallel processing distributes batch processing tasks across multiple computing nodes or cores. This can improve processing throughput and scalability, especially for very large workloads. It addresses the resource usage, scalability, and latency pain points.
Use Checkpoints and Retries
Use checkpointing and retry mechanisms to make the batch processing pipeline fault-tolerant. Checkpoints allow jobs to resume from a known state in case of failures. Meanwhile, retries automatically attempt to rerun failed job tasks. This practice addresses complexity and data integrity challenges.
Track and Tune Performance
Tracking batch processing jobs can help tune performance. Monitoring performance metrics helps identify bottlenecks and optimize resource usage for improved efficiency. This practice also addresses resource usage, scalability, and latency challenges.
Decouple Components
Design batch processing workflows with loosely coupled components. This will improve modularity, flexibility, and maintainability. Decoupled components make workflow maintenance easier. It also allows the reuse of components for other batch-processing jobs. This practice addresses complexity and maintainability.
Implement Error Handling and Logging
Use the error handling and logging mechanisms of batch processing frameworks and tools. Handling common errors in the processing workflow increases its fault tolerance. Meanwhile, logging helps in troubleshooting issues. This practice also addresses complexity and maintainability.
Use Data Partitioning and Sharding
Partition large datasets into smaller chunks or shards for more efficient processing. Data partitioning can help distribute processing tasks evenly across computing nodes. It can also reduce contention for shared resources. This practice addresses resource usage, scalability, and latency pain points.
Optimize Data Storage and Formats
Choose appropriate data storage formats and compression techniques. This will optimize storage efficiency and improve performance. Use columnar storage formats, compression codecs, and indexing strategies. But make sure it is tailored to the characteristics of the data and processing workload. This practice addresses resource usage and scalability challenges.
Real-World Examples of Batch Processing
Batch processing is widely used across various industries. The following are some industries and their corresponding usage examples.
Finance
-
Transaction Processing: Banks process millions of deposits, withdrawals, transfers, and payments daily.
-
Risk Management: Financial institutions assess and manage risks in investment portfolios and lending activities. They analyze market data, customer transactions, and other factors.
Healthcare
-
Electronic Health Records (EHR): Healthcare providers manage patient care and billing daily. They process medical records, lab results, and billing information to do these.
-
Medical Imaging Analysis: Healthcare organizations analyze X-rays, MRIs, and CT scan images to diagnose and treat diseases.
Retail
-
Inventory Management: Retailers manage inventory levels, optimize stocking, and prevent stockouts. So, they process sales data, inventory levels, and supply chain information.
-
Customer Analytics: Retailers wanted to personalize marketing campaigns and improve customer engagement. So, they need to analyze customer purchase history, demographics, and preferences.
Manufacturing
-
Production Planning: Manufacturing firms want to improve production planning and scheduling. So, they process data on raw materials, production schedules, and equipment performance.
-
Quality Control: Manufacturers analyze data from sensors, production lines, and quality inspections. So, they can ensure product quality and identify defects.
Telecommunications
-
Network Management: Telecom firms process call records, network traffic, and equipment performance. So, they can ensure stable network operations.
-
Customer Billing: Telecom providers process customer usage data to generate bills and manage customer accounts.
Transportation and Logistics
-
Route Optimization: Transportation companies process data on shipment volumes, vehicle capacities, and traffic conditions. This will improve route planning and scheduling.
-
Fleet Management: Logistics companies analyze data on vehicle locations, fuel consumption, and maintenance schedules. So, they can make sure fleet operations and maintenance are smooth.
Marketing and Advertising
-
Ad Targeting: Marketing firms process data on consumer behavior, demographics, and online activity. This will ensure targeted advertisements and effective promotional campaigns.
-
Campaign Analysis: Marketing teams analyze campaign performance data, including click-through rates, conversions, and ROI. This will help optimize marketing strategies and allocate resources effectively.

Batch Processing vs. Stream Processing
The following is a comparison table between batch processing and stream processing:
| Aspect | Batch Processing | Stream Processing |
|---|---|---|
| Processing Method | Processes bulk data at scheduled intervals. | Processes data as it arrives in real-time. |
| Latency | Higher latency as processing occurs in batches. | Lower latency as processing happens immediately. |
| Data Volume | Typically handles small to large volumes of data in batches. | Suited for handling small to very large data volumes by streaming small data continuously. |
| Use Cases | Well-suited for tasks that don’t require real-time responses, such as generating reports, data warehousing, and offline analytics. | Ideal for scenarios where immediate results are needed, such as monitoring systems, fraud detection, and real-time recommendations. |
Pros and Cons of Batch and Streaming Processing
| Batch Processing | Stream Processing | |
|---|---|---|
| Pros |
|
|
| Cons |
|
|
The choice between batch and streaming depends on the specific requirements or use case.
Conclusion
Data enthusiasts can develop their skills in batch processing along with other data processing techniques. This can provide organizations with many benefits to prepare reports and similar purposes.
In summary, we tackle use cases, benefits, limitations, how it works, pain points, and best practices. Handling batches can be simpler than a continuous stream of data. Beginners can start with batch processing. Later on, stream processing is the next skill to pursue. Use tools like Skyvia that balance ease of use and flexibility but produce robust data pipelines.
Batch processing can be a fun and fruitful process to learn. While it has challenges, many have succeeded by following best practices.