Articles • by Olena Romanchuk • November 21, 2025
Most companies collect data faster than they can make sense of it - apps churn out logs, CRMs overflow with customer details, and marketing tools keep exporting CSVs like it's a competitive sport. The result? Businesses drowning in data but somehow still starving for insights.
That is where data ingestion comes in. Literally, Uber for your data. It picks it up from wherever it's hanging out (databases, APIs, cloud storage, Karen's Excel file from 2019) and drops it off at a central spot where your BI tools and AI models are waiting with their appetites ready. Except, unlike Uber, the pickup locations keep moving, and half the passengers don't speak the same language.
In this article, we'll lift the curtain on how data ingestion really works - the methods, the moving parts, the tools worth your time, and a few myths that deserve early retirement. If you're ready to finally ingest data without indigestion, let's dive in.
Why Data Ingestion Matters
Data ingestion is the process that transforms scattered information into something usable and trustworthy. It's the bridge between data living in fifty (the number of sources might be shocking) different places and having one reliable source that makes sense, which is pretty much mandatory if you want to compete in today's landscape, where everything changes by Tuesday. Below, we explore why robust data ingestion is essential across industries and use cases.
What is Data Ingestion?
Data Ingestion is the process of importing structured and unstructured information from diverse sources, such as APIs, databases, cloud applications, and IoT devices, into centralized storage systems, including data warehouses, data lakes, or lakehouses.
Data ingestion cuts across every industry that can't afford to be slow or sloppy:
- Finance tracking money moving between accounts.
- Healthcare monitoring vitals continuously, identifying warning signs while intervention still works instead of during autopsies.
- Stores piecing together customer paths - website browsing that leads to app research that ends in physical store purchases, or doesn't.
- Logistics teams predicting where supply lines will clog before trucks are idling in traffic and customers are tweeting angry questions about their orders.
- Telecom networks staying ahead of capacity crunches.
- And many other industries where data efficiency and reliability are a must.
Speed matters because both opportunities and problems move quickly. Accuracy matters because decisions based on garbage data become expensive mistakes.
Simple batch uploads were once enough, but not anymore. What's taking over is this hybrid dance where real-time streaming and scheduled batches work in tandem, each covering what the other can't. AI and machine learning invested in this trend - algorithms don't wait politely for nightly data refreshes, they want updates now. That pressure's making organizations reconsider their entire approach to data: how fast it moves, how wildly it varies, how massively it scales when things get serious.
Data Ingestion vs. Other Approaches
All the existing data processing approaches seem to be alike. However, each process serves distinct purposes and is much different from the others than it looks.
Data Ingestion
- Definition: It drags scattered across systems like puzzle pieces in different rooms into one spot so someone can assemble the picture.
- Purpose: Because raw data sitting in random places doing nothing helps nobody. You need it corralled before APIs change, sources disappear, or that critical spreadsheet gets "accidentally" deleted.
ETL (Extract, Transform, Load)
- Definition: It pulls data from sources that clearly hate you, runs transformations that fix the seventeen different date formats, fills in blanks nobody bothered recording, and shoves the result into a data warehouse where business logic actually works.
- Purpose: Source data arrives looking like it fell down the stairs. Fix it before storage so the analytics team spends time finding insights instead of debugging why revenue's apparently negative.
ELT (Extract, Load, Transform)
- Definition: A modern processing approach where data is first extracted and loaded into the target system, and then transformed within that system.
- Purpose: To leverage the processing power of modern data warehouses for transformation tasks, allowing for scalability and flexibility.
Data Integration
- Definition: It drags data from silos that refuse to talk to each other and forces them into a unified view where relationships between things become visible instead of theoretical.
- Purpose: Fragmented data means fragmented decisions. People waste hours reconciling conflicting numbers or just guess. Integration fixes that by making data consistent and accessible, so analysis isn't crippled.
Comparison Table
| Aspect | Data Ingestion | ETL | ELT | Data Integration |
|---|---|---|---|---|
| Primary Function | Collect and import | Extract, transform, then load | Extract, load, then transform | Combine data from multiple sources |
| Transformation | Not involved | Performed before loading | Performed after loading | May involve transformation processes |
| Processing Location | Source or intermediary system | External processing engine | Target system (e.g., data warehouse) | Across various systems |
| Use Cases | Real-time collection, streaming | Data warehousing, compliance reporting | Big data analytics, cloud data lakes | Enterprise-wide data analysis |
| Latency | Low (real-time or near real-time) | Higher (due to the transformation step) | Lower (transformation post-loading) | Varies depending on implementation |
| Flexibility | High (supports various data sources) | Moderate (structured data preferred) | High (handles structured/unstructured) | High (integrates diverse sources) |
| Complexity | Low to Moderate | High (due to transformation logic) | Moderate (leverages the target system's power) | High (requires coordination across systems) |
Solving Core Data Challenges
Getting data ingestion right means solving a few critical problems that otherwise turn into expensive messes:
- Breaking the Silo Curse: Ingestion collects fragmented data scattered across systems, so everyone's working from the same playbook instead of conflicting fan fiction.
- Eliminating the Insight Time Warp: Old data breeds old decisions. Ingestion keeps your dashboards honest and current so you're reacting to reality, not a memory.
- Killing Manual Labor: Automated ingestion takes over the grunt work of moving data around, which means your team can spend time on stuff humans excel at - like thinking creatively or arguing productively.
- Starting with Clean Slate: Ingestion can scrub, validate, and dedupe right at intake, preventing insufficient data from metastasizing through your entire analytics stack like a digital virus.
Enabling Strategic Business Outcome
Solid data ingestion is what separates companies drowning in spreadsheets from those using their data:
- Intelligence You Can Trust: Timely, clean data helps teams identify opportunities among risks and risks that can and should be taken, rather than sifting through piles of motley insights in real-time, rather than discovering them in post-mortem meetings.
- Humans Finally Doing Human Work: Automation handles the boring logistics so your talented people can focus on strategy, models, insights, and basically anything more valuable than data janitorial work.
- Regulation-Proof Infrastructure: Proper ingestion supports governance from the ground up, keeping you compliant as privacy laws evolve faster than anyone can track.
Supporting Critical Use Cases
Strong ingestion pipelines are the foundation behind critical real-time systems:
- Fraud Detection: Financial platforms can analyze transactions as they happen, catching suspicious patterns while there's still time to stop evil.
- Dynamic Pricing: Airlines and hotel sites aren't guessing what to charge. They're watching what potential customers are doing right now, along with thousands of others, and adjusting prices every few seconds based on demand surges and competitor moves.
- Predictive Maintenance: Industrial operations stream sensor readings constantly to spot failing equipment before it turns into an expensive breakdown and a very bad Monday.
Built for Scale and Change
Effective ingestion accommodates growth across volume, velocity, and variety while absorbing schema evolution and business expansion without degrading performance or requiring constant rearchitecture.
- Scalability: Infrastructure scales from modest data volumes to massive ones without architectural overhauls every time growth accelerates beyond initial projections.
- Flexibility: Business evolution brings new sources and changing schemas constantly. Pipelines either accommodate change gracefully or turn into brittle systems requiring frequent intervention.
Relevance Across Industries
Data ingestion is not confined to a single sector. Its benefits are widespread:
- Finance: Flags suspicious transactions before the fraudster celebrates, evaluates credit risk in seconds instead of days, and mines customer data for patterns that shape billion-dollar strategies.
- Healthcare: Ensures medical staff see current patient information instead of potentially lethal, outdated records, supports diagnostics with fresh data, and tracks disease patterns before they explode into crises.
- Retail: Builds recommendation engines that genuinely understand what you want, anticipates inventory needs before you apologize for stockouts, and keeps stock levels synchronized instead of comically wrong.
- Information Technology: Monitors systems for warning signs before disasters strike, identifies what's degrading performance, and optimizes infrastructure through insight instead of expensive guesswork.
Types of Data Ingestion: Choosing the Right Approach
There are various options for moving records from a source to storage. The type of data ingestion you choose depends on velocity, business needs, and the speed at which you need insights.
Batch Ingestion
Rounds up and processes massive data hauls according to the clock, whether that's every hour, when everyone's asleep, or once the sun comes up. It packs records together before hauling them to their destination, like a data lake or warehouse.
- Best for: Old-school business dashboards, tracing trends over time, and stashing documents to keep regulators happy.
- Why it matters: It's dead simple to get running, easy on the wallet, and requires minimal hand-holding. Does the job brilliantly when your data isn't racing against time or when "good enough by morning" actually is good enough. But when the market's moving fast or conditions flip on a dime, this approach shows up fashionably late.
Real-Time (Streaming) Ingestion
Moves data at breakneck speed the moment it's created, leaning on streaming tech like Apache Kafka or Amazon Kinesis to capture and beam live data streams wherever they need to go.
- Best for: Blocking fraud while it's still warming up, monitoring IoT heartbeats as they happen, pulling off trades faster than a New York minute, and customizing experiences before users even realize what they want.
- Why it matters: You gain split-second intelligence and can act while the iron's hot, but you'll need infrastructure that's built like a tank, capable of processing endless data streams without hitting the wall.
Micro-Batching
Micro-batching gathers small batches of data over very short intervals, typically every 15-60 seconds, and then processes them as mini-batches.
- Best for: Log ingestion, clickstream analytics, and user behavior tracking.
- Why it matters: You're cutting lag time versus traditional batch jobs while dodging the resource black hole that comes with industrial-strength streaming. It's your go-to when you need data that's fresh-ish, close enough to now that it's still useful, without signing up for the architectural headache of keeping streams running 24/7.
Hybrid Ingestion
Blends batch and streaming under one roof using Lambda or Kappa architectures. You're not choosing between speed and depth anymore. Real-time streams get processed immediately for decisions that can't wait, while batch copies pile up quietly for the complex analysis where you actually need to think instead of just reacting.
- Best for: Companies tired of choosing between "fast and scrappy" versus "slow and thorough," who want both the instant hit and the full documentary.
- Why it matters: You're not stuck choosing between speed and substance. Act on breaking developments while quietly amassing the kind of data history that makes for killer trend analysis, smarter models, or bulletproof audit trails.
| Type | Latency | Use Cases | Complexity |
|---|---|---|---|
| Batch | High (minutes-hours) | Reports, historical analytics | Low |
| Real-time | Low (ms-seconds) | Fraud detection, real-time dashboards | High |
| Micro-batching | Medium (seconds) | Log processing, user behavior | Moderate |
| Hybrid | Varies | Mixed-use (real-time + batch) | Moderate-high |
Different types of data ingestion exist because data itself is so varied. Some move fast, and some do not. The most effective pipelines combine the right approaches for the right workloads. The key is knowing what's mission-critical right now and what can wait.
How the Data Ingestion Process Works: A Step-by-Step Guide
Every dashboard that updates instantly, every report that makes sense, every alert that fires before disaster strikes - there's a data ingestion pipeline behind the scenes doing the unglamorous work of moving the right information to where it needs to be, in formats that don't break everything.
Below, we concocted an eight-step process that most modern ingestion workflows follow:
Step 1: Identify Data Sources
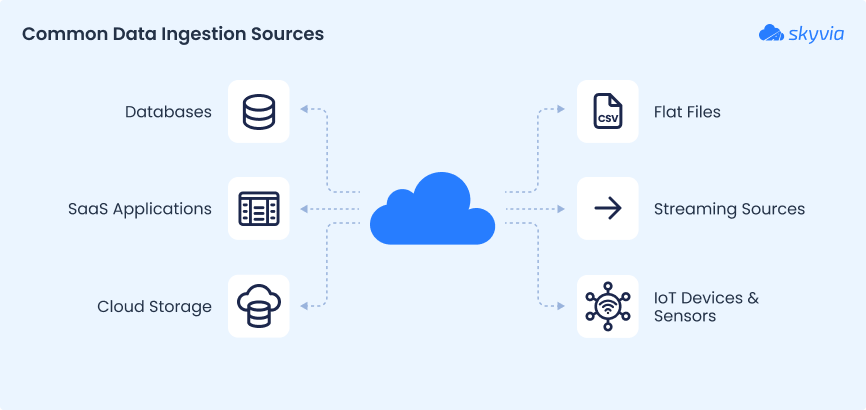
Knowing your sources sets the foundation for designing the pipeline. These involve only the data sources that are relevant to current requirements. It can include:
Databases
On one side, you've got relational databases like MySQL and PostgreSQL running a tight ship, while non-relational options like MongoDB and Cassandra operate with more breathing room. Both types are stashing structured and semi-structured data across every business system in your arsenal. They're the scaffolding beneath your transactional powerhouses - e-commerce sites closing deals, CRM systems tracking every handshake and follow-up, all the mission-critical stuff.
SaaS Applications
Salesforce owns your customer relationships, HubSpot runs your marketing plays, and QuickBooks keeps the books balanced. These platforms are where the real action lives. Feeding their data into your analytics engine means you're working off the same sheet of music as everyone pounding keyboards across sales, marketing, and finance.
Flat Files
Formats such as CSV, Excel, or TSV remain widely used for ad hoc file sharing or historical data imports. Often stored locally or in cloud drives, they're commonly imported during migrations or audits.
Cloud Storage Services
Platforms such as AWS S3, Azure Blob Storage, and Google Cloud Storage are used for large-scale file storage, backups, and data lakes. These are popular landing zones for raw ingestion before processing.
Streaming Sources
Systems like Apache Kafka and Amazon Kinesis enable real-time data collection. Ideal for use cases like fraud detection, live monitoring, or personalization engines.
IoT Devices and Sensors
Field-deployed gear like smart meters, wearables, and vehicle trackers generate endless data streams about whatever they're monitoring. Smart city sensors tracking traffic flow become particularly useful when they're feeding real-time conditions into planning systems or helping fire trucks find routes that aren't currently parking lots.
Now that you know where to drill, get the credentials to access them. Then, form the connection strings, file paths, URL of the APIs, or other ways to open each data source. Once connected to the sources, identify the tables or objects where the data resides.
Step 2: Select Ingestion Method
Choose how to get data based on how fast you need it:
- Batch ingestion loads data on scheduled intervals, ideal for periodic reporting.
- Real-time or streaming ingestion handles continuous data flows, supporting use cases like fraud detection or live monitoring.
- Hybrid ingestion mixes both approaches to fit varied sources and business needs.
Step 3: Choose the Right Data Ingestion Tool
Start by choosing the platform running your ingestion, not halfway through when you've already hit walls. What fits depends on your sources, ingestion approach, transformation complexity, growth trajectory, and how much money you're willing to light on fire.
Cloud services, open-source tools, paid ETL/ELT solutions - they each have their place. Get this choice right early, and pipelines stay robust while maintenance stays manageable instead of becoming everyone's least favorite task.
Step 4: Extract Data
When the method and tool are defined, proceed to data extraction. It is vital to first collect or copy data from your sources.
The goal here is to accurately retrieve all relevant data while minimizing impact on source systems. Sometimes, extracted data is temporarily held in staging areas before further processing.
Step 5: Validate and Clean
Never trust data blindly. Solid validation protects your pipeline from various issues. If you don't want to pull garbage through the whole pipeline, then do at least the minimum clean-up:
- Remove duplicates.
- Handle missing or inconsistent values.
- Validate types and formats.
Step 6: Data Transformation (Optional but Common)
Where your data is heading and what you're trying to learn from it shapes how you transform it. Some setups transform before loading (ETL), while others dump everything first, then transform (ELT). Whichever path you take, transformation bends data into shapes your business logic understands and your reports can use efficiently.
Step 7: Load Data into Destination
Drop everything into storage - data lakes for the flexible types, warehouses for the structured crowd, lakehouses for the indecisive. Snowflake, BigQuery, Redshift, they all work. The point is getting data somewhere people can query it without Slack-begging the engineering team, visualize it without downloading files manually, or feed it into models without playing data courier every single time someone needs fresh inputs.
Step 8: Monitor and Maintain the Pipeline
Launching the pipeline is merely act one. The sequel that determines success is monitoring:
- Alerts that catch failures or data going sideways before stakeholders start asking uncomfortable questions.
- Logs that show bottlenecks emerging before they choke pipelines into unusable sluggishness.
- Routine audits find schema tweaks or API changes that silently murder functionality.
Pipelines that get this care scale alongside ballooning data instead of collapsing spectacularly, keeping insights moving instead of stopping mysteriously because nobody noticed something upstream changed and broke everything.
Key Data Ingestion Challenges (and Solutions)
Sounds straightforward enough: connect, extract, move on with your life. Then you actually build it and discover problems breeding in places you didn't know existed, corrupting data silently or breaking pipelines in creative ways that make retrospectives uncomfortable.
Here are the traps everyone hits and what keeps you from falling into them.
Inconsistent or Poor Data Quality
- Problem: Data shows up with duplicate records, missing values, typos, and format inconsistencies. All of that collides to make your team's working day long and tiresome.
- Solution: Embed validation and cleaning early in the pipeline architecture, not bolted on later when things are already broken. Choose tools that validate schemas strictly, eliminate duplicates ruthlessly, and profile data actively so quality degradation gets stopped before it reaches anything downstream.
Performance Bottlenecks
- Problem: Inefficient ingestion methods will make the entire data processing effort finish late. It will have performance issues when the data grows bigger. Other factors that will impact performance are slow network latency and resource contention.
- Solution: Take your time choosing the right method and planning. Carefully estimate all possible scenarios and potential developments. Test the capacity of your data pipeline.
Handling High Volume and Velocity
- Problem: Millions of records screaming through your pipeline every minute, or batch jobs so huge they make your servers weep, that's when systems start giving up on life.
- Solution: Cloud platforms like Snowflake, BigQuery, AWS Glue don't flinch at volume; they scale resources up when traffic explodes, back down when it chills. Kafka plays middleman, queuing up the chaos so your downstream processes aren't trying to drink from a fire hose and failing spectacularly.
Security and Compliance Risks
- Problem: Shuttling personal details, credit card numbers, or medical histories between systems is basically tempting fate. One slip and you're dealing with breached data, furious customers, and regulators writing very expensive letters.
- Solution: Encrypt the whole journey so data is protected whether it's moving or parked. Use tokenization and ensure GDPR/CCPA compliance. Masking and role-based access controls (RBAC) also help secure ingestion pipelines.
Schema Drift
- Problem: Changes in source schema (new columns, changed types) can silently break pipelines or corrupt target tables.
- Solution: Implement schema monitoring and automated alerts. Use platforms that offer schema evolution support or dynamic mappings to adapt safely.
Complex Integrations Across Diverse Sources
- Problem: Try connecting data from ten different apps with their own weird formats and API personalities, and you'll end up with a Frankenstein pipeline of custom scripts that breaks whenever a vendor sneezes.
- Solution: Tools like Skyvia, Informatica, or Fivetran ship with connectors already built. Instead of writing yet another API integration from scratch, you configure settings and move on. New sources get added in hours, not sprints, and engineering stops babysitting connector code.
Data Ingestion Tools and Technologies
There's no single approach. Different tools and frameworks are built for different environments, skill sets, and business demands. Here's how the landscape breaks down.
By Category
Open Source Tools
These tools give you full access to the source code, making them ideal for teams that want to customize, self-host, or fine-tune their pipelines. On the one hand, you get flexibility. On the other hand, the responsibility for setup, scaling, and support is also yours.
Proprietary Tools
Commercial tools arrive with the good filling. Interfaces that make sense, connectors that work without debugging, and support people who know what they're talking about. You ship faster.
The price? License fees that feel reasonable at first but grow with scale, and before you know it, migrating off the platform might be disruptive enough that organizations often defer it despite better alternatives emerging.
Cloud-Native Tools
These run straight in the cloud, scaling automatically without you dealing with the servers 24/7 or playing the "will this be enough capacity?" guessing game. Great when you need to move quickly or when traffic behaves unpredictably and you'd rather not overpay for idle resources.
On-Premises Tools
Regulated organizations often can't escape on-prem. Auditors demand it, compliance frameworks require it, and legal won't approve anything else. You own the whole stack, which means you also own every hardware failure, every security patch, and everything that breaks.
By Approach
Hand-Coded Pipelines
Fully custom, built from scratch. These pipelines offer precision and control but demand significant engineering effort and ongoing maintenance.
Pre-built Connectors and Workflow Tools
Designed for rapid integration, these tools simplify setup through drag-and-drop interfaces or config-based pipelines. Sometimes they offer less flexibility when use cases get complex.
Data Integration Platforms
All-in-one platforms aim to handle ingestion, transformation, and delivery in a single system to tame tool sprawl, though many still need serious technical knowledge to configure and scale properly.
Skyvia follows that unified model but sheds the typical complexity weight even a bit more:
- Pre-built connectors skip the custom integration grind.
- No-code interfaces open pipeline building beyond just engineers.
- Smart scheduling adapts to changing data volumes.
- Incremental loading reduces unnecessary reprocessing
In practice, you get: fewer competing tools, emergency fixes that don't happen at ungodly hours, and an ingestion layer that small teams can confidently operate without feeling perpetually overwhelmed.
DataOps-Driven Ingestion
DataOps works because it fixes the broken telephone game that ingestion usually becomes. Engineers stop guessing what analysts want, analysts stop discovering data's unusability after it arrives, and governance stops auditing disasters after they're live. Collaboration happens upfront, automation removes friction, and pipelines move from idea to production without the usual drama.
Approach/Tool Comparison
| Approach/Tool Type | Flexibility | Ease of Use | Scalability | Best For |
|---|---|---|---|---|
| Open-Source Tools | High (Customizable) | Low (requires expertise) | Depends on infrastructure | Teams that need full control/custom logic |
| Proprietary Tools | Moderate (limited by vendor features) | High (user-friendly interfaces) | High (vendor-managed) | Quick deployments with vendor support |
| Cloud-Native Tools | Moderate to High (depends on service) | High (minimal setup) | High (auto-scaling) | Cloud-first organizations |
| On-Premises Tools | High (full control over environment) | Moderate (IT support needed) | Limited (hardware-bound) | Highly regulated environments |
| Hand-Coded Pipelines | Very High (fully custom) | Low (developer-driven) | Depends on design | Complex, tailor-made use cases |
| Pre-built Connectors and Workflow Tools | Low to Moderate (predefined options) | High (designed for usability) | Moderate | Fast setup with basic needs |
| Data Integration Platforms | High (broad feature set) | Moderate (requires setup/config) | High | End-to-end pipeline orchestration |
| DataOps-Driven Ingestion | Moderate (automation + collaboration) | Moderate (process-driven setup) | High (automated pipeline scaling) | Teams focusing on efficiency and agility |
How to Choose the Right Solution for Data Ingestion?
The best tools help organizations build resilient, intelligent pipelines that adapt to business needs. Choosing the right toolset is about balancing flexibility, control, and scalability while reducing the engineering effort to maintain workflows. Below, we list the features and capabilities inherent in the best tools on the market.
Multimodal Ingestion Capabilities
Modern platforms support batch and real-time streaming, often within the same architecture. This flexibility allows teams to handle structured and unstructured data from cloud, on-prem, and edge sources with equal ease.
- Schedule-driven batch processing for routine loads.
- Real-time pipelines for low-latency updates (e.g., event streams, IoT feeds).
- Micro-batching options to balance speed and efficiency.
Universal Connectivity
Effective ingestion tools come with a broad set of pre-built connectors for seamless integration across:
- Relational and NoSQL databases.
- Cloud storage systems.
- SaaS applications and APIs.
- Message queues and event brokers (Kafka, MQTT, etc.).
These connectors reduce the need for custom scripts and speed up integration with third-party systems.
Embedded Data Quality and Validation
Reliable pipelines ensure data is clean, consistent, and usable. Built-in quality features may include:
- Schema enforcement and anomaly detection.
- Deduplication, null handling, and field mapping.
- Real-time validation against data contracts.
Governance, Security, and Compliance
Ingestion tools are increasingly responsible for enforcing privacy and security policies during movement:
- Encryption in motion and at rest.
- Access control and identity management.
- GDPR, HIPAA, and SOC 2 alignment features.
- Audit trails for compliance verification.
Automation and Pipeline Orchestration
Enterprise-scale ingestion often involves dozens of sources and complex workflows. Tools now include automation layers to:
- Orchestrate jobs with triggers, dependencies, and retries.
- Monitor ingestion pipelines in real-time.
- Automatically adapt to schema changes or source outages.
Scalability and Deployment Flexibility
Whether deployed in the cloud, on-premises, or in hybrid setups, ingestion platforms must scale horizontally and handle volume bursts without manual intervention.
- Elastic cloud-native architecture.
- Edge ingestion support for IoT and mobile devices.
- Multi-region and cross-cloud support for distributed teams.
Advanced Data Ingestion Use Cases
The use cases below highlight the critical role of data ingestion in driving innovation and efficiency across various sectors:
Real-Time Fraud Detection in Banking
Financial institutions combat fraud effectively. For instance, a leading U.S. bank implemented a sophisticated ingestion and mapping system to enhance its fraud detection capabilities. This practice results in significant financial savings and operational efficiency.
IoT Analytics in Smart Cities
Smart cities utilize IoT devices deploy IoT networks gathering urban data at scale: connected public transport, traffic monitoring, infrastructure sensors. Real-time ingestion powers these systems, enabling operational optimization and better citizen services by processing information as conditions change rather than hours later.
Customer Onboarding in SaaS
SaaS companies are automating customer data ingestion to accelerate onboarding processes. Automated pipelines help organizations pull customer information fast, enhancing user experience and speeding up time-to-value.
AI Model Training and Personalization
Enterprises like Netflix employ data ingestion pipelines to feed machine learning models for content recommendation and personalization. These pipelines help process vast datasets, allowing for real-time content suggestions and improved user engagement.
Best Practices for Effective Data Ingestion
Following these best practices helps ensure your pipelines are efficient, resilient, and ready to scale.
Define Clear Objectives
Requirements and objectives should be clear from the start.
Tip: Align the types of data to ingest, its sources, and intended use to business goals.
Prioritize Data Quality Early
Data ingestion is not just copying records to a target location. The copy needs to be validated for accuracy, completeness, and consistency. The ingestion process should check for missing values, duplicate rows, and other quality checks.
Tip: Set up schema enforcement and notify teams of any schema drift.
Choose the Right Ingestion Method
Match your ingestion strategy to your use case. Batch jobs may be fine for daily reports, but real-time needs streaming.
Tip: Use micro-batching for near real-time performance with lower infrastructure costs.
Automate Wherever Possible
Manual data transfers don't scale, and they're prone to errors. Use workflow orchestration tools to automate ingestion jobs, schedule updates, and handle retries automatically.
Tip: Automate alerts for job failures, delays, and load mismatches.
Design for Scalability and Performance
Design the ingestion process to reduce latency and maximize throughput.
Tip: Use approaches like incremental updates, parallel processing, and compression techniques. Then, choose scalable architectures, distributed processing frameworks, and cloud-native services to handle large-scale ingestion.
Monitor Pipeline Health
Constant performance monitoring spots slowdowns creeping in, data vanishing mysteriously, or connections dying quietly - all before executives start asking why the numbers look wrong.
Tip: Pay attention to metrics such as throughput, latency, error rates, and source availability.
Documentation
Encourage knowledge sharing, ease troubleshooting, and address personnel movement through proper documentation. Catalog information about the data source, format, schema, lineage, and traceability to keep and share the internal expertise.
Documentation should include updated requirements, goals, objectives, metadata, and other relevant information. That will guarantee ongoing maintenance, support, and improvements.
Tip: Keep records of how data moves, what relies on what, staying functional, which processing steps happen in which order, and what transformations twist data into its final shape. Transparency is what saves you during audits and stops compliance teams from treating your pipeline like a black box they don't trust.
Continuous Improvement
Use feedback, performance metrics, and ever-changing business needs to see where you're standing. It allows users to identify opportunities to improve the efficiency and effectiveness of the current ingestion situations, even if those opportunities hide beneath piles of logs.
6 Common Data Ingestion Myths (and the Truth Behind Them)
Believe the wrong things about how this works, and suddenly timelines evaporate, dashboards become expensive modern art that displays nothing useful, or costs metastasize in ways that make CFOs start asking pointed questions. Time to kill some myths that just won't die.
Myth 1: "Data Ingestion Is Just so Simple"
Fact: The beginning always looks deceptively simple, but volume changes that equation fast. You'll face duplicate records, missing values, evolving schemas, and performance issues. Scaling takes planning, tools, and ongoing oversight.
Myth 2: "All Data Needs to be Ingested"
Fact: More information doesn't always mean better results. Pulling in every available record can overwhelm your systems and cost you a fortune. Focus on what's relevant and actionable for your business goals.
Myth 3: "Data Ingestion is a One-Time Activity"
Truth: Even with automation, ingestion isn't a one-time action. APIs may break, schemas may change. Data quality issues may occur. There's no setting and forgetting it here because systems degrade without attention. Monitoring surfaces issues early, tuning prevents performance from sliding into the red zone, where nobody's happy.
Myth 4: "Technology Solves Everything"
Truth: Even the best tools can't fix a strategy that has flaws. Successful ingestion depends on clear goals, good governance, and collaboration between teams.
Myth 5: "Real-Time Ingestion Is Always Better"
Fact: Real-time sounds impressive, but it's not always needed. They drain budgets fast. If your reports refresh daily or weekly instead of every second, batch ingestion makes more sense and won't murder your cloud bill.
Myth 6: "You Need a Big Data Team to Do This Right"
Fact: Sure, the really complicated tasks still need someone who's seen some things. But building basic-to-solid pipelines is not gatekept by engineering anymore.
Conclusion
One theme runs through all of this: ingestion determines whether your data infrastructure works or disappoints. It's not glamorous, but it powers every insight, report, and prediction downstream. Strong ingestion means faster queries, cleaner analysis, and trustworthy results. Weak ingestion means constant firefighting, chasing discrepancies, explaining why metrics shifted overnight, and questioning whether any of it's accurate.
Real-time pipelines are becoming the norm, not the upgrade. Automation is stepping in where manual workflows used to clog up. And with AI taking a bigger seat at the table, the tolerance for slow, fragile ingestion processes is dropping to precisely zero. The future of data ingestion is immediate, automated, and built to flex as fast as your business does.
If you're ready to move past scripts that are barely holding together, late-night pipeline rescues, and "did the job run?" anxiety, it might be time to bring in tools designed for this era. Skyvia can help you get there with no-code pipelines, 200+ connectors, automation already built in, and an ingestion layer that doesn't demand to devote a whole floor to your engineering team.
Curious what smoother data mornings feel like? Try Skyvia for free and build a pipeline that behaves itself. Your future dashboards will thank you.
FAQ
What is data ingestion, and why is it important?
Data ingestion is the process of collecting and importing data from various sources into a central system, such as a data warehouse or data lake. It's essential for analytics, real-time decision-making, and machine learning by making raw data accessible and usable.
What are the different types of data ingestion?
There are several core types: batch ingestion, real-time ingestion, micro-batching, and hybrid ingestion.
How does data ingestion differ from ETL or data integration?
Data ingestion is about moving data from one or more sources into a destination system. ETL and ELT involve an additional transformation step. Data integration is a broader concept that includes ingestion, transformation, and the unification of information across systems.
What are the most common challenges in data ingestion?
Some of the biggest ingestion challenges include scalability, latency, data quality, and integration complexity.
How do I choose the right data ingestion tool?
Look for tools that support both real-time and batch processing, offer automation and monitoring, work with required sources and formats, scale easily with your data volume, and provide a user-friendly interface or API access.
Can data ingestion be automated?
Absolutely. Most modern platforms support automated pipelines triggered by schedules or real-time events. Automation reduces manual errors, speeds up data flow, and ensures pipelines run consistently, even across complex environments.