Articles • by Edwin Sanchez • March 28, 2024
Data replication is the process of making and keeping copies of the same data across diverse locations. This practice not only fortifies business continuity. It also positions data closer to its users scattered across regions.
Data replication ensures that critical information is available, regardless of geographic distances. The idea might seem daunting. Yet the rewards are profound.
This introductory exploration aims to demystify data replication for both learners and enthusiasts. It will shed light on its intricacies and the tangible benefits it brings to the forefront. This will also discuss challenges and best practices.
Let's dive in.
Why is Data Replication Important?
See why data replication is so important to an organization's data management strategies from the following benefits below:
-
Faster Data Access: Data replication reduces latency. Latency refers to the delay in data transmission. Know that the farther the data is to the user, the slower the data access is. By replicating data across various locations, data becomes closer to the users. Since the data is closer to them, information is sent and received at a faster rate.
-
Improved Scalability: Data replication enhances scalability. Scalability refers to the system's ability to handle increasing data volumes. This also involves increased network traffic and workload. As a result, user experience remains smooth over time even if data is still growing.
-
Faster Disaster Recovery: Data replication is a crucial part of disaster recovery plans. It enables swift recovery from cyberattacks, outages, and data corruption.
-
Higher Fault Tolerance: Data replication improves fault tolerance. Scalability refers to the system's resiliency in the event of failures. With multiple copies of data, the loss of one copy does not mean the end of business operations.

How Does Data Replication Work?
How the ETL process works is obvious from the acronym itself. The image below describes it.
Data replication, in simple terms, works by copying data to one or more locations. That is the obvious part. But it operates through various mechanisms.
Replication can occur:
- within a local area network (LAN),
- within a wide area network (WAN),
- from LAN/WAN to the cloud,
- or within the cloud.
It all depends on the system requirements on where the replication will happen.
Replicas can be synchronous or asynchronous to create.
Synchronous Replication: Data is mirrored in real-time between source and target databases. In other words, data is written to the primary storage and replica at the same time. It ensures consistency but potentially introduces latency.
Asynchronous Replication: Involves writing the data in the primary storage first. Then, it writes to the replicas afterward. It offers flexibility and cut performance impact.
Understanding these replication models helps to customize data replication strategies for your needs.
The size of the data to replicate also dictates how it works. It can either be full or partial.
Full Replication: This aims to copy the entire database to all replication sites. For example, a company has a main branch in Zurich, Germany, and hosts the primary database. Its branches in the United States, Hong Kong, and Australia will have the exact copy.
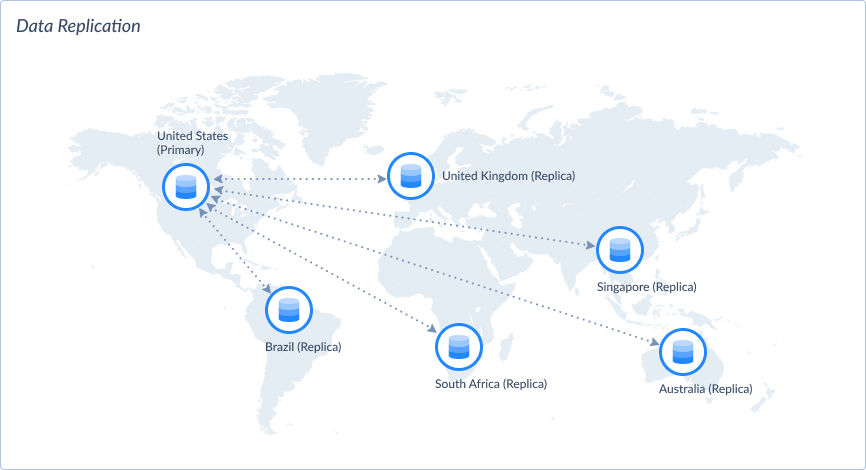
Partial Replication: This aims to copy a part of the primary database to replication sites. The primary database has all the data. The replication sites will have portions of data that matter to them. For example, the primary database is in the United States. It includes all data from all sites. The sites in Brazil, South Africa, the United Kingdom, Singapore, and Australia will have copies of data with transactions done in their area. When there are changes in each site, those changes are replicated back to the primary site. See a sample below.
Steps in Managing a Replication Project
- 1. Plan for Data Replication:
-
- Gather stakeholder requirements and goals.
- Define data requirements by identifying what to replicate.
- Based on goals, plan for security, scalability, performance, and compliance.
- 2. Choose the Replication Technology:
-
- Software: There are many tools in the market to replicate data. Choose the one that is easy to use but will not compromise processing speed.
- Hardware: Choose between on-premises infrastructure, cloud, or the hybrid of the two.
- 3. Configure the Hardware and Software for Replication:
-
- Choose the replication model, type, and configuration (these are discussed in the next sections)
- Set up and configure the servers based on the chosen replication configuration.
- Configure the replication software.
- Specify the tables to replicate in the replication software.
- 4. Run and Test the Replication:
-
- Do quality checks on the replica after running the replication process.
- Test the replicas with the applications that access them.
- Note the problems encountered and fix them until it's ready for deployment.
- 5. Deployment to Production:
-
- Set up and configure production servers and networks for all planned locations.
- Deploy and make the replication process online.
- 6. Monitoring:
-
- Monitor and document replication performance and other problems.
- Fix the problems accordingly.
Steps in Replicating a Database Table
Each database table undergoes steps to replicate into the target location. Here they are:
- 1. Capture Changes:
- Using the chosen replication technology, identify and record alterations in the source data. One technique to do this is using
- 2. Data Extraction:
- Extract the changed data from the source database.
- 3. Data Transfer:
- Send the changed data to the target database.
- 4. Data Loading:
- Insert the changed data into the database copy.
- 5. Data Consistency Checks:
- Verify the consistency of replicated data.
- 6. Logging and Monitoring:
- Record replication activities and track performance.
- 7. Security Measures:
- Apply encryption and authentication for secure replication. This also ensures compliance to security and privacy regulations.
Data Replication Configurations
There are several configurations to consider in implementing data replication. Described below are the common ones. But it’s a must to learn about these terms first:
- Nodes:
- In a distributed computing system, a node generally refers to a single computational unit. It can be a server or virtual machine, that is part of a larger network or cluster. Each node may host one or more copies of the data. Together, they form the distributed infrastructure for data replication.
- Publisher (or Master):
- This is a component responsible for generating and sending data changes to other components. The publisher initiates the replication process by making changes to the data. Then it broadcasts those changes to one or more subscribers.
- Subscriber (or Slave):
- This is a component that receives and consumes data changes sent by the publisher. Subscribers subscribe to the data changes. Then it applies those changes to their own databases to keep them synchronized with the publisher.
A node can be a master or a slave. Or in other words, a publisher or a subscriber. Even more, a node can both act as a publisher or subscriber, as you will see in the following replication configurations:
Master-Slave Replication
In master-slave replication, one node (the master) serves as the primary source of data changes. Meanwhile, one or more other nodes (the slaves) replicate data from the master.
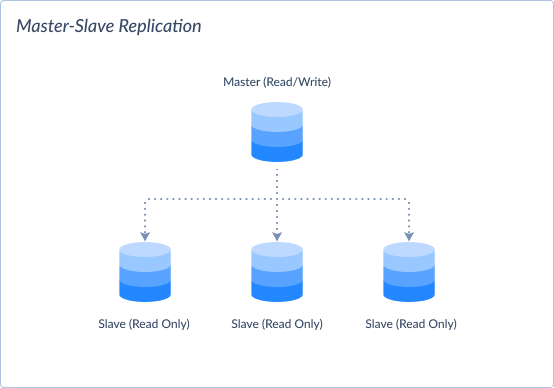
- Model:
- Asynchronous.
- Pros:
-
- Simple to put in place and manage.
- Provides a centralized point of control for data changes.
- Cons:
-
- Single point of failure: If the master node fails, replication halts until it is restored.
- Potential scalability limitations due to reliance on a single master.
- Inconsistencies may occur during high-write volumes.
Master-Master Replication
In master-master replication, multiple nodes act as both master and slave. It allows bidirectional data replication between them. But it requires conflict resolution mechanisms.
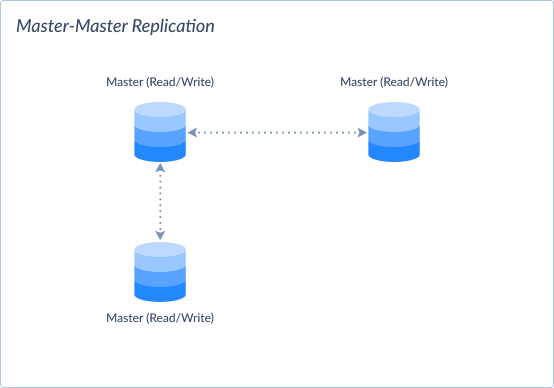
- Model:
- Can be Synchronous or Asynchronous.
- Pros:
-
- Provides better scalability and fault tolerance compared to master-slave replication.
- Allows for read and write operations on any node, distributing the load.
- High availability, good for geographically distributed systems.
- Cons:
-
- Requires conflict resolution mechanisms to handle conflicting data changes.
- Complexity increases as the number of master nodes grow.
Peer-to-Peer Replication
In peer-to-peer replication, all nodes in the system are equal (peers). It replicates data directly with each other. All nodes share the responsibility to replicate even if there's no designated master node. It requires agreement protocols and conflict resolution.
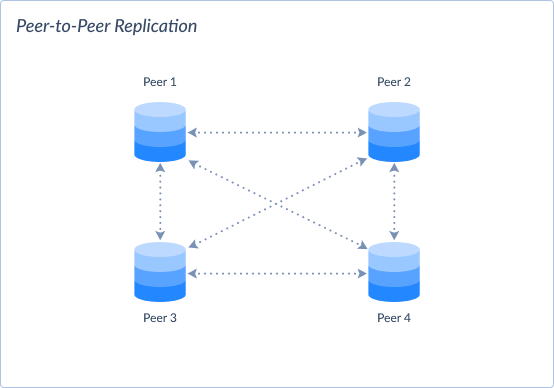
- Model:
- Can be Synchronous or Asynchronous.
- Pros:
-
- Decentralized architecture provides better resilience and fault tolerance.
- Data changes can propagate directly between nodes, reducing latency.
- Cons:
-
- May require additional complexity for conflict resolution and consistency maintenance. The decentralized nature makes it more complex than master-master replication.
- Synchronization overhead increases as the number of peers grows.
Ring Replication
In ring replication, nodes are organized in a circular topology. Each node replicates data to its adjacent nodes in the ring. Writes happen in one node and then propagate to adjacent nodes.
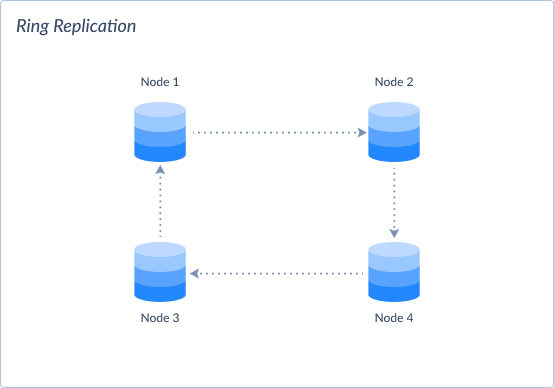
- Model:
- Typically, asynchronous.
- Pros:
-
- Provides redundancy and fault tolerance by propagating data changes throughout the ring.
- Simple topology that scales well with the number of nodes.
- Cons:
-
- Limited scalability compared to other configurations. Each node only replicates data to its adjacent neighbors.
- Susceptible to data inconsistencies if nodes are not synchronized properly. If replication fails in one node, succeeding nodes are now inconsistent.
- Complex initial setup. Potential delays in updates reaching all servers. It also requires consistent hashing for data distribution.
Hierarchical Replication
In hierarchical replication, nodes are organized in a hierarchical structure. This means parent nodes replicate data to child nodes. It is a mix of master-slave and master-master at different levels. This is suitable for large-scale deployments.
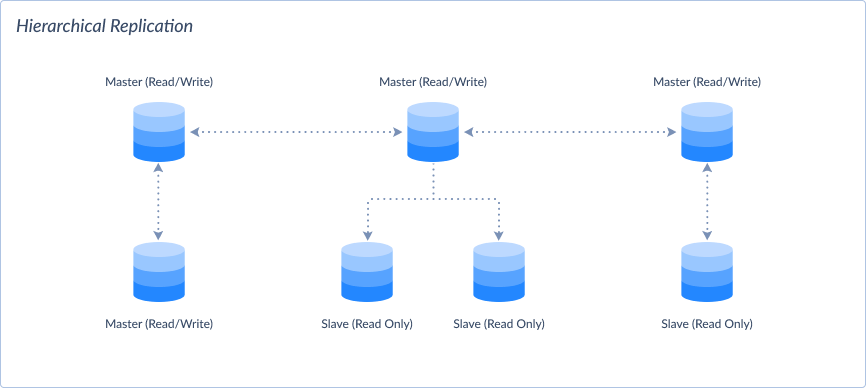
- Model:
- Can be Synchronous or Asynchronous.
- Pros:
-
- Provides centralized control and management of data replication.
- Allows for data propagation from higher-level nodes to lower-level nodes, providing scalability.
- Cons:
-
- May introduce latency and synchronization issues in large hierarchical structures.
- Data inconsistencies may occur if the parent and child nodes are not kept in sync.
Each replication configuration has its own trade-offs. Complexity, scalability, fault tolerance, and consistency depend on the chosen configuration.
Types of Data Replication
Data replication encompasses various methods and approaches tailored to specific requirements. Here are some common types:
Transaction Replication
- Description:
- This involves replicating individual database transactions from a source to a target database. This happens in real-time or near real-time in a continuous fashion.
- Example:
- A retail company replicates sales transactions from its online store. This propagates to different continents to make data closer to their customers.
Snapshot Replication
- Description:
- Merge replication combines data changes from multiple sources into a single, unified dataset at the target.
- Example:
- A multinational corporation replicates customer data from various regional databases to a central CRM system. It consolidates updates from different locations.
Data replication can also be classified based on the data format of all copies. It can either be homogenous or heterogeneous.
Homogeneous Replication
- Description:
- Homogeneous replication involves replicating data between databases of the same type and structure.
- Example:
- A company replicates data between two MySQL databases to ensure redundancy and disaster recovery.
Heterogeneous Replication
- Description:
- Heterogeneous replication replicates data between databases of different types and structures. This is less common compared to homogeneous replication.
- Example:
- A company replicates data from a SQL Server database to an Oracle database to ease integration with a new application. SQL Server has thisbuilt-in replication feature.
Understanding these types helps to choose the best approach based on requirements.
Data Replication Scenarios and Use Cases
Scenario 1: Multiplayer Online Gaming
- Description:
- Players across the globe engage in multiplayer online games through desktop and mobile devices.
- Use Case:
- Game data are replicated across game servers in different regions. This data includes player profiles, game progress, and in-game assets. Replication ensures improved availability and reduced latency for players worldwide.
- Benefits:
-
- Faster gaming experience across desktop and mobile devices.
- Synchronized and consistent gaming experience regardless of location and device.
Scenario 2: Online Freelancing Services for Employers and Freelancers
- Description:
- Companies worldwide use an online platform to hire freelancers for various projects.
- Use Case:
- Hiring and work data are replicated across servers in different continents. This data includes contracts, work progress, evaluation, and payments. This replication enhances scalability, improves performance, and ensures business continuity.
- Benefits:
-
- Faster data access due to redundant data copies.
- Enhanced working experiences for both companies and freelancers.
Scenario 3: Global Weather Data
- Description:
- Weather data is collected from diverse locations. Then, it is made available globally through a website, a mobile app, and an analytics platform.
- Use Case:
- Replication across distributed servers ensures improved availability for users and analysts.
- Benefits:
-
- Optimized performance for the mobile app and website.
- Improved data availability for analysts, facilitating better decision-making processes.
Data Replication Pain Points
Despite its benefits, data replication comes with its own set of challenges. Here are some common pain points:
- Complexity: Managing diverse replication tools and processes across environments can be complex and resource-intensive.
- Cost: It is a challenge to balance the cost of extra storage and bandwidth for replication with budget constraints. Cloud environments may also introduce unexpected costs due to resource scaling.
- Performance: Maintaining application performance while replicating data across networks can be hard. Even more so when dealing with large datasets or high-latency connections. This includes replicating from on-premises to cloud environments.
- Security: Protecting sensitive data during replication poses security risks. It needs robust encryption and access control measures.
- Scalability: Accommodating increasing data volumes and changing replication needs is also a challenge. Doing it while maintaining performance can strain resources and infrastructure.
- Disaster Recovery: Companies want to lessen downtime and data loss in case of outages or disasters. Ensuring reliable and timely data recovery needs comprehensive planning and testing.
- Compliance: Meeting data privacy and regulatory requirements adds complexity to data replication processes. This is especially so in highly regulated industries. It may also vary in different locations.
- Data Loss and Inconsistencies: Data loss or inconsistencies during replication can occur due to network issues, software bugs, or human errors. This leads to data integrity issues and business disruptions.
Addressing these pain points needs data replication best practices to ensure effectiveness and reliability.
Data Replication Best Practices
Organizations can adopt the following best practices to address data replication pain points:
- 1. Comprehensive Planning:
-
- Develop a thorough replication strategy. This should align with business objectives and address specific requirements.
- 2. Robust Infrastructure:
-
- Invest in reliable hardware and network infrastructure to support data replication processes. This will lessen performance bottlenecks.
- 3. Regular Monitoring and Optimization:
-
- Use monitoring tools to track replication performance and identify potential issues proactively.
- Optimize replication settings and configurations based on performance metrics and changing requirements.
- 4. Data Encryption and Security Measures:
-
- Implement robust encryption protocols to secure data during replication and at rest.
- Enforce access controls and authentication mechanisms to prevent unauthorized access to replicated data.
- 5. Testing and Validation:
-
- Conduct regular testing and validation of replication processes. This will ensure data integrity and consistency.
- Verify the effectiveness of disaster recovery plans through simulated scenarios and drills.
- 6. Scalability Planning:
-
- Anticipate future growth and scalability requirements when designing replication architectures.
- Ensure scalability by implementing flexible replication solutions. This should cover increasing data volumes and changing business needs.
- 7. Comprehensive Documentation:
-
- Maintain comprehensive documentation of replication configurations, processes, and procedures.
- Provide training and resources to IT staff. This will ensure proper understanding and execution of replication tasks.
- 8. Continuous Improvement:
-
- Foster a culture of continuous improvement. Ask for feedback from stakeholders and implementing lessons learned from past experiences.
- Stay updated with advancements in replication technologies and best practices. Whis will optimize efficiency and effectiveness.
By following these best practices, organizations can enhance their replication processes. This will ultimately drive business success and resilience.

Skyvia's Replication Tool
Skyvia's replication tool is more related to ELT than data replication. It creates a copy of cloud data in a database and keeps it up-to-date automatically rather than creating and maintaining other instances of the same data source.
Thus, Skyvia replication is useful for ELT scenarios of copying data to the database for further analysis and reporting. But database replication is outside of the scope of tasks that this tool solves.
Conclusion
Organizations seek to enhance resilience, accessibility, and performance in their data management efforts. Data replication emerges as a critical tool for them. Throughout this exploration, we've delved into its intricacies. We uncovered its importance, mechanisms, challenges, and best practices.
By replicating data across diverse environments, organizations can achieve faster data access. They can also improve scalability, enhanced disaster recovery capabilities, and higher fault tolerance. But navigating its complexities needs adherence to best practices.
In conclusion, it's clear that data replication is an attainable goal. Organizations should embrace comprehensive planning, robust infrastructure, and continuous improvement to do it. So, they can harness the power to drive business success and resilience in a data-driven world.
Let this exploration serve as a roadmap for your data replication journey.