Articles • by Serhii Bykov • September 17, 2023
When you are building a data-driven business or just working with data, you start meeting lots of data-related terms, like ETL, ELT, reverse ETL, data pipelines, etc. However, when you know them closer, you’ll see that they are not too complex to understand. In this article, we explain what ELT is.
First of all, ELT is a method of moving data from one place or tool to another. However, these words describe all the abbreviations and terms listed above. So, what makes ELT stand out in this set of terms?
The main distinction of ELT is that data are taken from the source and loaded to the destination as they are, without modification on the way. All the data preparations for analysis, cleansing, deduplication, etc. are performed in the destination, after loading.
Another distinction is that in ELT, the target is almost always a data lake or data warehouse. While ETL is also often used to load data into a data warehouse, it’s not limited to such destinations.
Understanding ELT
Let’s proceed to a more formal definition of ELT and find out ELT meaning. ELT stands for Extract Load Transform – the three stages of the data loading process.
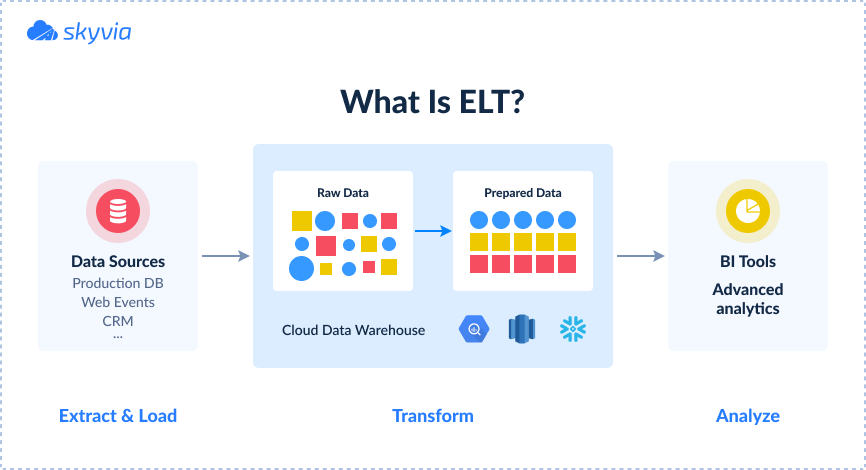
Extract
At the Extract stage, the data are retrieved from the source. The source can be a database, a cloud or desktop app, a file, etc.
Load
The extracted data are simply moved to the destination as is, without transformations at all or only with minimal ones, like type conversion. This allows speeding up loading and putting less effort into it.
Transform
In the ELT process, transformations are performed in the destination itself, after the data is loaded. Transformations use resources of the destination, which is usually a data warehouse or a cloud data lake with lots of computing power.

ELT vs ETL
The wide use of ETL pipelines in data management signifies that it’s quite a pretty valuable tool with a number of benefits.
Brief Introduction to ETL
As well as ELT, ETL is a process of moving data from one or multiple sources into a destination. However, the ETL approach assumes transforming data before loading them to the target. The data appears in the destination already cleansed and prepared for analysis, and the structure in the destination differs from the source.
Key Differences between ELT and ETL
Here are key ELT distinctions from ETL.
| ELT | ETL |
|---|---|
| Transformation is performed in a destination itself, after data is loaded. It is usually performed on demand. | Transformations are performed before loading data into a destination. |
| ELT process is mostly used for loading data into a data lake or cloud data warehouse. | ETL process is not limited by specific destinations only; the destination can be anything. However, it’s often used to load data into a database or a data warehouse. |
| ELT process can load structured and unstructured data. | ETL process is best suited for loading structured data. |
| The data extraction and loading process is very easy, and tools typically are very easy to configure. However, transformations configured in the destination or in the data analysis tool require SQL coding or advanced IT knowledge. | ETL process is usually configured in GUI editors; however, advanced transformations may have more complex editors or require coding. |
Use Cases for ELT and ETL
The choice between ETL and ELT is usually determined by data volume and speed requirements. In the ELT approach, data are transformed after loading, so data gets to a data warehouse or data lake faster, and data loading requires less computational power.
| When to use ELT | When to use ETL |
|---|---|
| When data volumes are huge. Data loading is much simpler with ELT, and data volume restrictions are less limiting. | When data volumes are terabytes or less. ETL approach requires decent computational resources for processing data before loading, and thus, cannot process as much data as ELT. |
| When data must be loaded to a destination fast and updated frequently. Since transformations are applied on demand, data are loaded much faster. | When speed and frequency of updates are less important. Transforming data every time it is loaded restricts the update frequency. |
| When there is no predefined schema in the destination. | When the destination already has predefined schema, to which data must be fitted. |
Benefits of ELT
ELT approach has a number of benefits over ETL:
- Data loading configuration is much simpler. When no transformations are performed, you only need to connect your tool to sources and destination.
- ELT provides higher performance. Data are processed and transformed on-demand in the destination itself; thus, the loading process requires less computational power.
- ELT is a more reliable process. Transformation is separated from loading, and even if transformation is incorrectly configured and fails, you still have your original data in the destination.
- ELT offers easier maintenance. The loading process is simpler and requires fewer configuration changes in case of data structure changes.
- ELT scales better. Data warehouses and data lakes, which store and transform the loaded data, are good at processing huge data volumes, so you’ll have no problem with an increased amount of data.
- ELT often costs less. Using cloud ELT tools, as well as cloud data lakes or data warehouses for destinations, allows you to avoid investing money into powerful hardware and its administration. However, you also need to consider that ELT may require storing more data than ETL, so you need to plan and calculate costs carefully.
- With ELT, all the data is stored in their raw form in your warehouse. If you need to analyze your data in more detail or build a new, different report, you won’t need to change anything in your data loading process or reload all the data.
The Evolution of ELT
Historical Context and Shift from ETL to ELT
It is not very clear when the ELT approach first appeared. It was introduced approximately at the end of the 1990s – beginning of the 2000s as a response for ETL challenges. Businesses needed greater flexibility in data integration as requirements and data sources started to change more frequently and rapidly. ELT became the solution since it’s a more flexible approach that can be repurposed for different data sources more easily.
Another important difference is that ETL pipelines load data in batches every so often. There are real-time data pipelines that load each new or modified record immediatelyData volumes also kept growing, putting strain on traditional ETL tools. ELT approach allowed processing larger data volumes, which led to higher adoption of ELT.
But the key factor that made ELT possible and feasible was the rise of cloud MPP data warehouses and Big Data technology.
Role of Cloud Data Warehouses and Big Data in Rise of ELT
The appearance of cloud data warehouses with massively parallel processing, like Amazon Redshift, Google BigQuery, Snowflake, etc., made possible both affordable storage for huge amounts of data and the ability to process large data sets without the need to prepare and transform data in advance. They first made it possible to load data unchanged and perform transformations on-demand when analyzing data and creating reports.
The second important factor was the development of scalable and powerful data transformation and analysis frameworks like Python, Apache Spark, R, etc. They enabled the possibility of fast transformation and analysis of huge data volumes.
Future of Data Integration
Growing Popularity of Data Lakes
The ELT process keeps evolving, and now data lakes appear more often as ELT destinations. Data lakes are high-capacity data storages that store raw data in their native format. They have flat architecture and don’t use hierarchical structures to store data. They have an on-demand system for data reading, looking, and analysis.
The process of switching to data lakes is aided by the progress of data cataloging and discovery solutions, like Alation, Amundsen, Data.World, IBM Watson Knowledge Catalog, etc. They enable you to search and analyze different data stored in flat storage in different raw formats.
Role of ELT in the Future of Data Integration
With the current tendencies of data volumes increasing, cloud storage and computing power becoming more affordable, and data discovery and analysis tools – better and easier to use, the role of ELT will probably grow over time, replacing ETL in more and more cases.
A wider spread of No-SQL databases, which are way harder to work with in the ETL approach, will probably aid switching to ELT even more. Being more flexible, suitable for a broader range of data sources, and able to process more data faster, ELT is a future of data integration.

ELT in Practice
Let’s finish our article with real-world examples of companies using ELT and see how ELT has improved their data management and business intelligence.
TitanHQ
TitanHQ is a leading SaaS Cybersecurity Platform delivering a layered security solution to prevent user data vulnerability. TitanHQ used the following data sources: Redshift data warehouse, SugarCRM, Tableau BI tool, Maxio payment processor, and a ticketing platform. First, they used Python scripts to extract data from their systems and put them into Redshift for data analysis.
They found out that Redshift did not wholly suit their needs and decided to migrate to Snowflake. They also wanted to replace their Python scripts with an ELT tool to automate moving data from SugarCRM into the data warehouse.
After analyzing several competitors, they chose Skyvia’s replication to perform the ELT task. The SugarCRM data is now moved automatically to Snowflake, and TitanHQ can analyze their data in Snowflake with Tableau and have a 360-degree customer view.
Convene
Convene designs and provides spaces for meetings, events, and conferences by partnering with the largest landlords in commercial real estate. They used a number of different data sources for different purposes, including Salesforce, Marketo, AWS, and others. They needed to turn data from these sources into knowledge for better understanding of the processes.
Convene decided to use Tableau + Redshift for analysis and reporting because they already had been using AWS, and they wanted to employ the ELT approach for collecting their data into Amazon Redshift. They chose Skyvia’s replication tool to perform ELT.
They successfully created a data warehouse in Redshift and automated loading data into it, including the most recent data. This improved their data reporting and analysis, making them more efficient.
Conclusion
ELT process and data lakes seem to be the future of data integration and analysis. ELT leverages businesses’ abilities to analyze large volumes of data from different sources, making the data loading process easier, faster, and more reliable. Many companies have already adopted this approach for their data analysis and reporting. We hope that this article helped understand what ELT is and its benefits.