Articles • by Edwin Sanchez • May 25, 2024
A data warehouse is a central repository of data collected from various sources to support data analysis, machine learning (ML), and artificial intelligence (AI).
The need for a centralized repository is not overhyped. Businesses today gather and record data into different operational systems, structures and data formats. If you collect, transform, and store data in a data warehouse, you get access to easier data querying, aggregation, categorization, and more.
In the end, a single version of truth provides a consistent and organized environment. This allows access to data to analyze it and make reports out of it. The generated insights from data warehouses can drive business strategies and operations forward.
Data warehousing concepts have been around since the late 80’s. At first, data warehouses live on-premises. Today, they are also available in the cloud with expanded benefits.
Data enthusiasts interested in making a data warehouse need to learn the concepts, technologies, and steps. This article will provide the basics and the general steps in creating a data warehouse.
What is the Purpose of a Data Warehouse?
The use of a data warehouse supports the following purposes:
- Consolidate Siloed Data. Data from different operational systems are in various formats and locations. Data silos form barriers to collaboration. It leads to operational inefficiency and limited insights. Querying and analyzing them are also close to impossible. Gathering them into a central repository will reduce these barriers.
- Enable Reporting and Dashboards. Once data is in a central repository, reports are easier to generate. With these, seeing the big picture in business operations becomes easier.
- Making Informed Decisions. Reports and dashboards enable better decisions. It helps in facing business challenges, seeing a new opportunity, reducing costs, and more in a proactive way.
- Implementing Machine Learning and Artificial Intelligence. Historical data helps organizations learn from past and present state of a business. Predictive analysis takes it to the next level through machine learning and AI. This is possible with the use of a data warehouse.

What are the Benefits of a Data Warehouse?
A data warehouse offers benefits compared to decentralized data from operational systems. Here are some of them:
- Improved Data Quality and Consistency: Data quality improves during validation and cleansing. This consistent and cleaner data is a better source for analysis and reports.
- Centralized Data Repository: Joining data from various sources and formats in one query is hard to do, if not impossible. It will also run slowly compared to querying from a single location. Querying and analyzing becomes easier and runs faster once data are in a data warehouse.
- Historical Data Analysis: Data warehouses contain historical data. This allows organizations to track trends and changes over time. The results are time-series analysis, year-over-year comparisons, and more.
- Separation of Concerns Between Transactional and Analytical Processing: Generating reports and analysis can be resource-intensive depending on the requirements. It may disrupt day-to-day transactions if processing occurs in the transactional database. Separating transactional processing from analytics is a good idea for quicker response times.
- Improved Decision-Making: Making major business decisions guided by guesses and emotions is a disaster. With a data warehouse, decisions are data-driven. Businesses can enjoy better strategic planning, customer insights, and more.
Data Warehouse Layers and Components
Making a data warehouse requires layers and components that will work together to gather, process, store, and analyze data. The following are the typical ones:
- Data Sources: This is where the data will come from. It includes data from transactional systems, devices, log files, and other formats.
- Data Integration Layer: This is where extraction, transformation, and storage happen. Data pipelines that will do these processes belong here. How data will reach the data warehouse depends on the requirements. It can be Extract, Transform, Load (ETL) or Extract, Load, Transform (ELT).
- Staging Area: Usually, this is a temporary storage of raw data from different sources. It is in the form of a relational database like PostgreSQL. This allows a single format for all disparate sources that makes transforming easier. Data cleansing and validation also occur here using transformation tools such as dbt.
- Data Storage Layer: This is the layer of the data warehouse in its final, consistent form. This is also a relational database designed to support fast querying.
- Data Access Layer: Sometimes referred to as Consumption Layer. This is where users retrieve and analyze data using tools from the data warehouse. These are business intelligence and analytical apps that can visualize data. Examples of these tools are Power BI and Tableau. Tools for multidimensional analysis are also within this layer.
- Data Governance and Security Layer: This layer provides user permissions to the data warehouse. It also enforces data governance policies.
Data Warehouse Architecture
A typical design of data warehouses is divided into tiers:
- Top-tier: This is where users interact with data using tools for analysis, data mining, and reporting. This includes interactive reports and dashboards that slice and dice on data and visualize them through different types of graphs.
- Middle-tier: This is the analytics engine like an OLAP server for fast querying and analysis. Examples are SQL Server Analysis Services (SSAS), Oracle Essbase, and IBM Cognos. Cloud data warehouses like Snowflake also have OLAP features as a foundational part of the database schema.
- Bottom-tier: This is a database server for loading transformed data. The format can be a star or snowflake schema.
Data Warehouse Schemas
Part of learning about data warehouses is designing the bottom tier of the architecture or the Data Storage layer. A good design will make data integration easier and querying for reports and analysis faster.
Before we proceed to data warehouse design, there are key terms to consider:
- Fact table: This is a table at the center of the schema. It is surrounded by other tables called dimensions (described next). It contains the facts about a business process or entity. Examples are product sales, human resource movements, helpdesk support tickets, and more. There can be several fact tables in a data warehouse, each sharing dimensions.
- Dimension table: This is a table that categorizes records in fact tables. Examples are store locations, company departments, or inventory items. A time dimension is also used to group transactions in the fact table for date and time analysis.
- Measures: A numeric column in the fact table that allows calculations. A data warehouse should have something quantifiable or there is nothing to analyze. Possible calculations are summations, averages, counts, minimums, or maximums. Examples are sales figures, inventory item counts, maximum heat index, and more.
Designing data warehouses needs at least one fact table with a measure and several dimension tables. For example, for product sales, there should be a fact table with the sale date, the product bought, the store, and the sale amount (measure). Then, the dimensions include a time dimension to categorize by year, quarter, month, etc., a product dimension, and a store dimension. With this, a report can be created by categorizing sales by product, store, and month or year.
Let's check two common schema designs for data warehouses: a Star schema and Snowlake schema.
Star Schema
This includes a fact table surrounded by dimensions forming a star. It can also be described as a parent-child design. The fact table is the parent and the dimensions are the children. The following illustrates a star schema design:
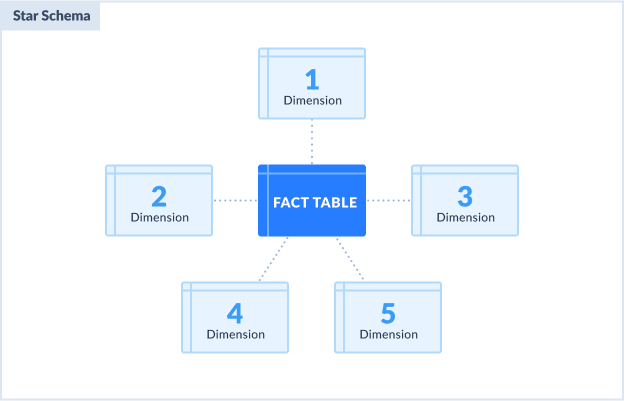
Star schema characteristics:
- The fact table is surrounded by dimension tables, forming a star.
- The primary keys in dimension tables are foreign keys in the fact table.
- No dimension table references another dimension table. They are denormalized.
Star schema advantages:
- Queries made out of this schema are simpler and easier to do.
- Faster queries because of the simple design.
- Easier to maintain.
Snowflake Schema
With Snowflake schema, dimension tables are more normalized. This means that a category can have subcategories. Compared to Star schema, dimensions can reference other dimensions. The following illustrates this:
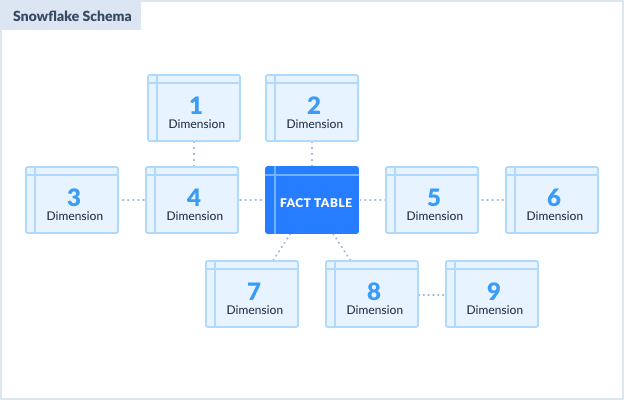
Snowflake schema characteristics:
- The fact table is also at the center and surrounded by dimension tables.
- Some dimension tables can reference first-level dimension tables. The table design is normalized compared to the Star schema.
Snowflake schema advantages:
- More flexible to changes in structure.
- Saves more disk space because of the normalized design.
Choosing Between ETL and ELT for a Data Warehouse
Another important concept to learn in data warehousing is how to update it. This refers to the Data Integration layer where you choose between Extract, Transform, Load (ETL) or Extract, Load, Transform (ELT).
ETL
ETL is the traditional approach to moving data from various sources into the data warehouse. It has the following characteristics:
- It starts by extracting data from one or more data sources.
- Next, the process performs data cleansing, validation, and transformation to conform to the schema design of the data warehouse.
- Finally, the process loads the transformed data into the data warehouse
This approach results in cleaner data. The data will also conform to data security and privacy regulations. However, errors may happen in the transformation stage. This problem will cause the data not to reach the data warehouse. That is why monitoring is a must to address the situation. Maintaining an ETL pipeline is also challenging when requirements change. The pipeline needs modification, testing, and deployment to apply the changes in production.
ELT
ELT is a data integration approach when the transformation is performed last. It has the following characteristics:
- Like ETL, it starts by extracting data from one or more data sources.
- Next, the process loads the raw data into a staging area.
- Finally, the process performs data cleansing, validation, and transformation.
This makes ELT faster to load large data sets. However, it needs higher compute resources in the destination for the transformation to happen. On-demand transformation is another plus in ELT, making it easier to maintain. Tools like dbt make the on-demand transformation easier and more maintainable.
Which Approach to Use
Both ETL and ELT can achieve similar outcomes to take data to the data warehouse. Each can conform to the data warehouse schema whether it is Snowflake or Star. The choice depends on the following factors:
- Data Volume: ELT is often a better choice when dealing with large volumes of data in various formats.
- Security and Privacy: ETL may be a better choice so as not to take sensitive information in another location, like the cloud.
- Maintainability: ELT is easier to maintain when adding more transformations.
- Resources: ELT is often more resource-efficient because it leverages the power of modern data warehouses.
Ultimately, the choice between the two will depend on the business and system requirements. When working with cloud-based data warehouses, ELT could offer advantages in flexibility and performance. If there is a need for strict control over transformations before loading, ETL might be the better choice.
OLTP vs OLAP in Data Warehousing
OLTP and OLAP have their places in data warehousing. This section discusses the differences between the two and their use cases.
OLTP
OLTP stands for Online Transactional Processing. This system supports operational systems like banking, insurance, inventory, and others. These systems are write-intensive and operate daily to record transactions in real time. The Data Sources Layer in data warehousing can be one or more OLTP systems.
OLAP
Meanwhile, OLAP stands for Online Analytical Processing. OLAP can be a valuable add-on to a data warehouse. It can support read-intensive queries of multidimensional data. In other words, it is not required in data warehousing.
OLAP can do operations like data slicing, dicing, pivoting, and drilling down large data sets. These are flexible ways to interact, analyze, and explore large amounts of data. Moreover, it is faster compared to plain SQL queries.
When OLAP Is Needed
OLAP is typically used in data warehouses in the following scenarios:
- Business Intelligence: OLAP is valuable when users need to perform advanced business intelligence tasks. Examples are multidimensional analysis, trend identification, and complex queries.
- Performance Optimization: OLAP systems are optimized for fast query performance. They often use specialized compact and fast storage structures like data cubes.
- Decision Support: OLAP helps business users make data-driven decisions. It can provide quick and intuitive ways to explore data from various angles.
- Historical Data Analysis: OLAP’s ability to handle historical data and analyze trends over time is beneficial for many business scenarios.
When OLAP Might Not Be Necessary
Some scenarios where OLAP might not be necessary include:
- Simple Reporting: If the data warehouse is for straightforward reporting without complex analysis, OLAP might be overkill.
- Operational Data: If the focus is on operational data or real-time reporting, OLAP’s multidimensional model is not a good fit.
- Resource Constraints: OLAP systems can be resource-intensive due to complex data processing and storage. If resources p are limited, simpler data warehouse approaches are a better ide li a.
When OLAP is not applicable, the following are common alternatives
- SQL Queries: SQL stands for Structured Query Language. This is the most common querying method when OLAP is not applicable.
- Business Intelligence Tools: Tools like Tableau or Power BI can provide analysis and reporting without OLAP systems.
Table of Differences
The following table states the main differences between OLTP and OLAP:
| Factor | OLTP | OLAP |
|---|---|---|
| Workload Focus | Write-intensive for real-time transactions | Read-intensive for large-scale analysis |
| Data Structure | Uses normalized data structures to avoid duplicates and maintain data integrity | Uses Star or Snowflake schema stored in a multidimensional model |
| Optimization Goals | Optimized for transaction speed and concurrency | Optimized for complex queries and analysis |
Data Warehouse vs. Data Marts vs. Databases vs. Data Lakes
Data professionals have a choice between different data storage and processing solutions. They need to choose which one will meet specific business needs. Data warehouses, data marts, databases, and data lakes vary in structure, purpose, scalability, and data types. Understanding their differences helps organizations choose the right solution for their data management and analytical requirements.
Table of Differences
| Feature | Data Warehouse | Data Mart | Database | Data Lake |
|---|---|---|---|---|
| Purpose | Centralized data repository for business intelligence and analytics | A portion of a data warehouse, focused on a specific business unit or department | General-purpose data storage for transactional operations | Large-scale storage for raw, unstructured, structured, or semi-structured data |
| Data Structure | Structured (star/snowflake schemas) | Structured (star/snowflake schemas) | Structured (normalized schemas) | Unstructured, semi-structured, and structured |
| Use Cases | Company-level business intelligence, complex queries, reporting, trend analysis | Department-specific analysis, reporting, and business intelligence | Transactional operations, data storage, and simple queries | Big data analytics, machine learning, exploratory analysis |
| Scalability | Scalable but may require specific resources | Scalable within a limited scope | Scalable depending on the platform | Highly scalable, designed for big data |
| Data Sources | Multiple sources, including operational databases, flat files, and cloud services | Typically derived from a data warehouse or specific data sources | Operational databases, applications, and user inputs | Raw data from various sources, including databases, files, and IoT devices |
| Data Transformation | ETL or ELT processes to transform data into structured format | ETL or ELT, usually derived from data warehouse transformations | Typically, minimal transformation (focus on transactional integrity) | Limited transformation, data often stored in raw form |
| Performance Optimization | Optimized for complex queries and analysis | Optimized for specific departmental needs | Optimized for transaction speed and concurrency | Designed for flexibility and scalability, not necessarily optimized for querying |
| Historical Data | Often contains historical data for trend analysis | May contain historical data for specific department | Stores data for current and historical transactions | Stores raw data for later analysis or transformation |
| Business Intelligence Tools | Supports business intelligence and analytical tools like Tableau, Power BI, and Looker | Often used with BI tools for department-specific analysis | Typically, not designed for BI tools | Can be integrated with BI tools but requires additional transformation |
Highlights
- Data Warehouses: Central repositories of structured data designed for business intelligence and complex analysis. They often involve ETL/ELT processes and support business intelligence tools.
- Data Marts: These are smaller subsets of data warehouses. It focuses on specific business units or departments. They are optimized for department-specific analysis and often derived from larger data warehouses.
- Databases: General-purpose storage systems used for transactional data. Databases prioritize transactional integrity and performance for transactional queries.
- Data Lakes: Large-scale storage for raw, unstructured, or semi-structured data. Data lakes offer flexibility and scalability. However, it needs additional transformation to integrate with business intelligence tools.

How to Make a Data Warehouse
Creating a data warehouse involves several steps. Here’s a comprehensive guide on how to make a data warehouse:
1. Define Business Requirements
Start by understanding the business needs and objectives. Identify the key stakeholders, such as business analysts, managers, or user champions. Then, gather their requirements. Ask questions like:
- What types of reports, report formats, and analyses will be needed?
- What business processes will the data warehouse support?
- What key performance indicators (KPIs) are important?
2. Design the Data Warehouse Architecture
Design an architecture that aligns with the business requirements. Consider the following elements:
- Schema Design: Choose between star or snowflake schema. This involves defining fact and dimension tables, along with the relationships between them. This also includes data marts to support various business units.
- ETL/ELT Processes: Decide whether ETL or ELT will fit the project needs. This will affect how to integrate data from source systems.
- Staging Area: Decide if there is a need for a staging area for temporary storage before final loading into the data warehouse.
- Data Storage Layer: Plan the structure of the data warehouse, including how data will be stored, organized, and partitioned. Also, decide if OLAP is applicable based on requirements.
3. Choose Data Warehouse Tools and Technologies
Select the tools and technologies that will support your data warehouse architecture. Consider:
- ETL/ELT Tools: Options are Apache NiFi, Talend, Skyvia, and Microsoft SQL Server Integration Services (SSIS).
- Data Warehouse Platforms: Cloud-based platform options include Amazon Redshift, Google BigQuery, Snowflake, or Microsoft Azure Synapse Analytics. If the data warehouse will reside on-premises, options include PostgreSQL, Microsoft SQL Server, or Oracle.
- Business Intelligence Tools: Tools for querying, reporting, and analysis, such as Tableau, Power BI, or Looker. Microsoft Excel is also an option for simple reporting and users are already familiar with it.
4. Implement Data Integration Processes
Create the ETL or ELT processes to extract, transform, and load data into the data warehouse. This involves:
- Extraction: Extract data from source systems, such as operational databases, flat files, or cloud services.
- Transformation: Clean, normalize, and aggregate data to fit the data warehouse’s schema. This step includes data cleansing, deduplication, and creating derived columns.
- Loading: Load transformed data into the data warehouse, organizing it into fact and dimension tables.
5. Establish Data Governance and Security
Use data governance practices to ensure data quality, compliance, and security. This includes:
- Data Quality Checks: Ensure there are no duplicate and missing data.
- Access Controls: Define user roles and permissions to control who can access data.
- Compliance and Auditability: Ensure the data warehouse complies with relevant regulations and policies. Establish audit trails to track data lineage.
6. Build Business Intelligence and Reporting
Create the user tools and interfaces that let them interact with the data warehouse. This involves:
- Business Intelligence Tools: Set up tools for users to query, analyze, and visualize data. Create reports, dashboards, and data visualizations.
- OLAP: Implement OLAP tools for multidimensional analysis, supporting complex queries and data exploration.
7. Test and Validate
Thoroughly test the data warehouse to ensure it meets business requirements. This includes:
- Data Quality Testing: Verify that data is accurate, complete, and consistent.
- Performance Testing: Test query performance and optimize as needed.
- User Acceptance Testing (UAT): Involve stakeholders to ensure the data warehouse meets their needs.
8. Maintain and Evolve
A data warehouse is not static. It can change as the business evolves. Implement ongoing maintenance and improvement processes. This will ensure the data warehouse continues to meet organizational goals.
By following these steps, you can create a robust and scalable data warehouse that supports business intelligence, analytics, and decision-making in your organization.
Data Warehouse Challenges
Beginners in data warehousing often face various challenges as they build their skills and experience. These challenges may come from technical, operational, or conceptual issues. The following are the common challenges and obstacles beginners encounter:
1. Learning Curve
There is a long list of things to learn in data warehousing. Beginners need to study concepts about databases, SQL, designing schemas, ETL, ELT, data analysis, OLAP, and more. They also need to learn the tools and technologies about these. With the steep learning curve, beginners may need years of experience with these concepts and tools to make a working data warehouse.
Here are some articles to get started learning these concepts:
- Mastering Data Integration – From Definition to Best Practices
- What is ELT?
- Understanding Batch Processing
- Understanding and Implementing ETL Processes
- Data Transformation: From Basics to Advanced Techniques
- Why Data Mapping is Essential for Business
2. Data Quality Issues
Data quality is a major challenge. Beginners and experts may spend more time cleaning and validating existing data. They may encounter inconsistent data, missing values, or incorrect data. These lead to errors in data analysis. Understanding data validation, cleansing, and governance processes requires time and practice.
3. ETL/ELT Complexity
On its own, ETL and ELT processes can be complex. Beginners may need a detailed understanding of data extraction, transformation, and loading. These along with a lot of practice and experience. They may find it challenging to build reliable ETL pipelines, deal with data integration, and manage dependencies.
4. Schema Design
Designing a good schema can be challenging at first. Even more, if the designer lacks experience in designing databases.
5. Performance Optimization
It can be difficult for beginners to identify bottlenecks and optimize queries. Techniques like indexing and partitioning may still be unknown to them. They need experience to see the impact of these techniques on performance.
6. Tool Familiarity
Aspiring data experts need tools for ETL/ELT, data querying, and business intelligence. Getting familiar with the tool that aligns with the concepts they already know may take time.
7. Data Security and Governance
Data warehouses may contain sensitive information. In this case, it requires robust security and governance practices. It can be challenging to implement access controls, ensure data compliance, and maintain data lineage. The worst case is ignoring the need for robust security in favor of meeting deadlines until a major issue emerges like a data leak.
8. Collaboration and Communication
Data warehouse projects involve collaboration among teams (IT, users, business analysts, data engineers, etc.). Communicating effectively, understanding business requirements, and collaborating on complex projects is a must. Ignoring this fact will cause problems in the data warehousing projects.
9. Keeping Up with Technology Trends
The field of data warehousing and analytics evolves rapidly. So, tools and technologies adapt to the changing landscape. Beginners and experts alike might struggle to keep up with the latest trends.
10. Understanding Business Requirements
Data warehouses are designed to support business intelligence and decision-making. Translating business requirements into technical solutions and ensuring that the data warehouse meets organizational needs can be challenging.
Overcoming Data Warehouse Challenges
To overcome these challenges, data professionals can take several steps:
- Training and Education: Grab the opportunity to participate in training programs, workshops, and online courses to build foundational knowledge.
- Hands-On Experience: Work on real-world projects and use cases, and take part in internships to gain practical experience. There are many examples online from various tools to start with hands-on experience.
- Mentoring and Collaboration: Experienced professionals are your lifelines in learning data warehousing. Collaborate with them and learn from their experience.
- Practice and Experimentation: Experiment with different tools and technologies. Practice building data warehouses and explore new techniques.
- Continuous Learning: Stay updated with industry trends, new technologies, and best practices. These are available through online resources, conferences, and networking.
Conclusion
As we have learned, data from various sources are difficult to analyze collectively without a data warehouse. Tools can interact with data warehouses to analyze these data and drive businesses forward.
While the learning curve is steep because of the various concepts, tools, and technologies to learn, it is not an impossible feat. Education, practical experience, and collaboration are ways to overcome data warehousing challenges.
Learning data warehousing is a fruitful journey. With the right attitude, data warehousing can become your very important skillset as a data professional.