Articles • by Edwin Sanchez • November 21, 2025
Discover what data synchronization is, how it works, and why it's essential for modern businesses. Learn about key sync methods, common challenges, and best practices to ensure data consistency across systems.
Picture a typical workday: sales data lives in CRM, finance runs in ERP, marketing fires from automation tools, support updates a helpdesk, and analytics hits the warehouse asking things like which channels drove new customers at what CAC and what next month is likely to look like. Same customer, five versions of the truth. A phone number gets fixed in one app but not the others, orders don’t match across systems, and reports drift out of sync. That’s the data silo tax most teams pay every day.
Data synchronization is how you stop paying it. In simple terms, it keeps records aligned across systems by propagating changes quickly and reliably, so "customer = Jane Doe" means the same everywhere. Whether you’re syncing Salesforce with NetSuite, HubSpot with a warehouse, or product data across Shopify and ERP, sync turns scattered updates into a single, consistent reality.
This guide is about data synchronization for 2025: what it is, why it matters, core patterns and architectures, real-world types and use cases, common pitfalls, and a clear framework for choosing tools that fit your scale, tech stack, and governance needs. By the end, you’ll know how to pick an approach that keeps data accurate, timely, and audit-friendly without adding operational drag.
What Is Data Synchronization in Simple Terms?
It is the process of maintaining consistent and up-to-date data across multiple systems by detecting changes and applying them where needed. In practice, if a record is edited in one app, sync propagates that update to the others, so every system agrees on the latest version. It can run one-way or two-way, in real time or on a schedule, but the goal is the same: one truth, no silos.
Modern businesses rely on hundreds of apps, including CRMs, ERPs, analytics tools, and cloud databases. For instance, Okta’s 2025 report says the global average number of apps per customer has topped 100 (up 9% YoY).
They don’t live in one system anymore. They live in a hybrid, remote, always-on world. Data has to move fast and stay accurate.
Think of real-time dashboards in finance, patient records in healthcare, inventory across retail stores, or SaaS platforms syncing customer data between regions. Without sync, you get delays, duplicates, and mistakes.
Below is a sample data sync of legacy and cloud CRM contacts. It shows the state of the contacts before and after the synchronization.

With synchronization, records of contacts on both systems are updated and consistent.

Why Data Synchronization Matters
Businesses collect data from everywhere: apps, devices, websites, teams, and even partners. But here’s the catch: those sources don’t always talk to each other.
The result? Data silos. Sales sees one version of a customer. Support sees another. Finance sees something else entirely. It’s like everyone’s reading a different script. As companies grow, so does this chaos. More tools, more teams, and more chances for things to go out of sync. That’s where data synchronization comes in. Not just to share data, but to unify it.
Syncing breaks down silos. It brings together tools that were never designed to work together. It makes sure every system and every person, works with the same facts in real time, so decisions are faster, smarter, and more aligned.
Key Benefits of Data Synchronization
Data sync is not just a mindless copying of data across systems. Check out the following benefits:
-
Better decision-making with consistent, up-to-date information.
Example: A retail chain syncs POS data with inventory systems in real time. Managers instantly see what’s selling and adjust stock levels or promotions across all stores, no guesswork. -
Faster workflows through automation instead of manual updates.
Example: A SaaS company connects its CRM and billing platforms. When a deal closes in the CRM, the billing system auto-generates invoices. No one has to retype data or chase approvals. -
Improved customer experience by giving every team the full picture.
Example: A customer contacts support about a delayed order. The agent sees shipping info from logistics and payment status from finance, all in one dashboard. The issue gets resolved in minutes, not hours. -
Stronger compliance and reporting with accurate, complete records.
Example: A healthcare provider syncs patient data between clinics and their central EHR system. Audits and reports are faster and more accurate, helping them meet HIPAA requirements without stress. -
Easier scaling as systems grow without breaking connections.
Example: A fintech startup expands to new regions. With data sync in place, their core platform integrates with local banking APIs and reporting tools. No need to rebuild the system from scratch.
Data Synchronization vs. Other Concepts
It’s easy to mix up data terms. Sync, integration, replication, migration. They all sound pretty similar at first. But in practice, they serve different purposes.
Let’s walk through how data synchronization stacks up against the rest.
Data Synchronization vs. Data Integration
Data synchronization is about keeping multiple systems in step. If one changes, the other updates too. Think of it like syncing phone contacts through your email. Change a number in one place, and it updates everywhere.
Data integration is about combining data from different sources into a single system. Unlike synchronization, it doesn’t update the original sources; it simply consolidates the data into one unified view.
Example: A CRM system pushes sales data to a central analytics platform each day. That’s integration. But if a customer’s email changes in the CRM and it auto-updates in the support system, that’s synchronization.
Data Synchronization vs. Data Replication
Both synchronization and replication involve copying data. But data replication is more like a one-way mirror, a replica of the same information and format. See an example of replicating the same data across different regions below:
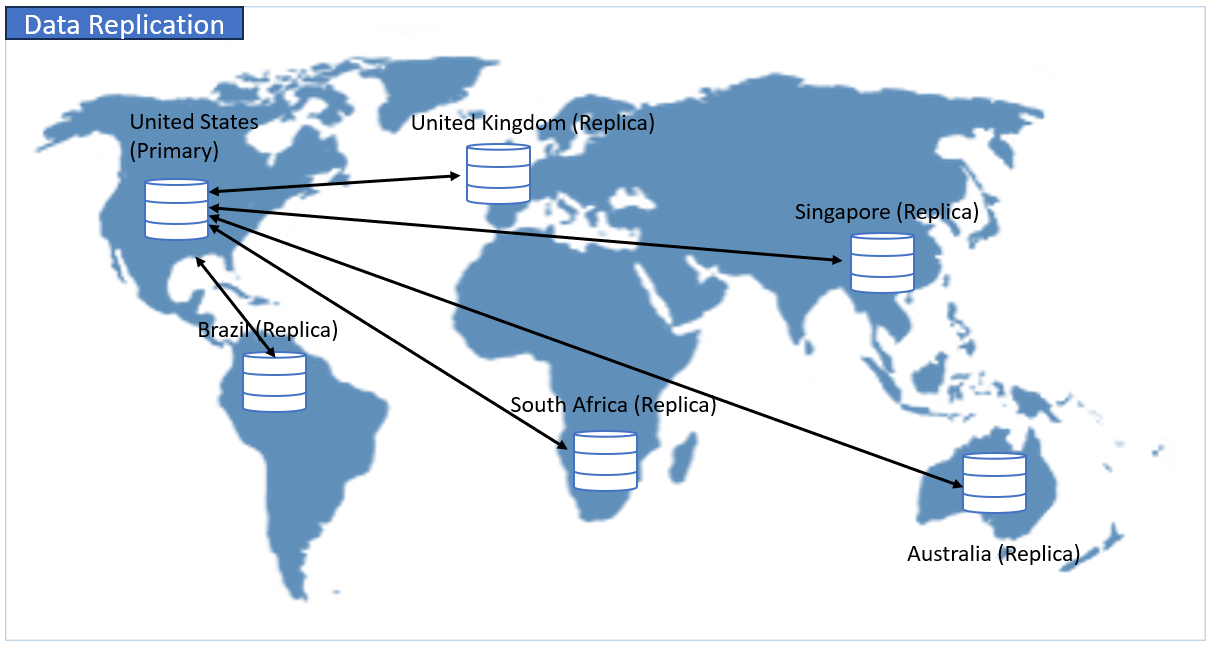
In replication, data is copied as is from one storage system to another. It’s often used for backup, disaster recovery, or improving performance by placing data closer to users. Synchronization copies the same information in different formats, making sure that changes are reflected in both systems.
Example: The team decides to replicate a production database to a read-only reporting server. That way, analysts can run heavy queries without slowing down the live system.
Data Synchronization vs. Data Migration
Now this one is clearer: data migration is usually a one-time thing. It moves the data from one system to another, often during upgrades or platform changes. Once the move is done, that’s it. No sync, no updates.
Sync is continuous. It’s designed to keep systems updated in real time (or near real time), handling changes as they happen on both sides.
Example: A company decides to move all its old HR data to a new cloud system. That’s migration. But if they keep their HR system and payroll system in sync, so employee details stay updated in both, that’s synchronization.
Quick Comparison Table
| Concept | What It Does | Direction | Timing | Example |
|---|---|---|---|---|
| Data Sync | Keeps data in sync between systems | One-way / Two-way | Continuous | Updates in CRM auto-reflect in Helpdesk |
| Integration | Combines data into one place | One-way | Batch / Real-time | CRM, Ads, and Website data into dashboard |
| Replication | Copies data exactly to another system | One-way | Continuous | Read-only copy of production DB |
| Migration | Moves data permanently to a new system | One-way | One-time | Transferring data to a new HR platform |
5 Common Data Synchronization Use Cases
Data synchronization shows up in more places than most people realize. Whether it’s sales, operations, or customer support, you name it, syncing data avoids confusion and saves time. Let’s walk through five real-world scenarios where data sync makes a big difference.
Keeping CRM and Marketing Tools in Sync
Sales and marketing teams often use different platforms. One handles customer details; the other manages outreach. If their tools don’t “talk” to each other, things get messy. Contacts get missed, or the same person gets emailed twice.
Example: A software company captures leads through a HubSpot form. As soon as someone submits it, their details sync straight into Salesforce. Now the sales rep can follow up immediately, and marketing can track what happens next—without emailing spreadsheets back and forth.
Syncing Online Store Inventory with ERP
Running an online store means you always need to know what’s in stock. If the inventory isn’t accurate, customers could order something that is not available. That leads to cancelled orders and bad reviews.
Example: A retail business sells items through Shopify and manages supply through NetSuite. When someone buys a product, NetSuite updates the quantity, and Shopify shows the change instantly. This prevents overselling and helps the warehouse team stay ahead.
Moving SaaS App Data to Cloud Warehouses
Most companies use a bunch of cloud apps—Stripe for billing, Zendesk for support, Google Ads for campaigns. But pulling data from all those places to build reports can be a hassle.
Example: A subscription service syncs customer charges from Stripe and support tickets from Zendesk into BigQuery. Now the data team can track how billing issues or slow support affect customer churn: all in one place, without chasing data across dashboards.
Syncing HR Platforms and Payroll Systems
Employee changes happen often: new hires, promotions, someone leaving. If HR and payroll systems aren’t updated together, mistakes can slip through. Paychecks might be wrong, or tax info might be off.
Example: An HR manager enters a raise in BambooHR. That update flows into ADP, adjusting the salary and deductions for the next payday automatically. Nobody has to remember to enter it twice.
Connecting POS Systems with Accounting Software
Retail shops rely on accurate sales data. But when the point-of-sale system isn’t linked to accounting software, someone ends up exporting files and fixing errors manually.
Example: A bakery uses Square at the counter and QuickBooks for bookkeeping. Each night, the day’s sales, tips, and taxes sync over automatically. The owner gets clean records without extra work and fewer surprises at tax time.
Types of Data Synchronization
Data doesn’t always move the same way or at the same pace. Sometimes it’s just a copy from point A to point B. Other times, systems need to talk to each other constantly, back and forth.
In this section, we’ll walk through two ways to think about data sync:
-
By direction. How data flows between systems
-
By timing. When the data moves
Understanding these helps teams pick the right sync setup for their use case and avoid messy surprises later on.
Let’s start with how data travels between systems. Is it a one-way street? A two-way conversation? Or more like a roundabout with multiple exits?
By Direction
Direction refers to how data travels between systems. It could be one-way, two-way, or even more complex setups where multiple sources stay in sync.
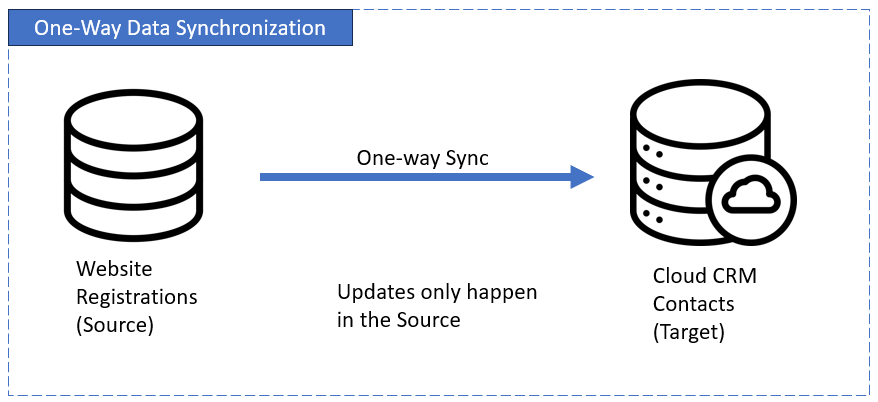
One-Way Synchronization
In one-way sync, data flows in a single direction from a source to a destination. The source sends, the destination listens. That’s it.
 When it fits best:
When it fits best:
This works well when pushing data into a system that doesn’t need to talk back, like a reporting tool.
Example:An online store sends daily order data to a business dashboard. The dashboard never pushes anything back.
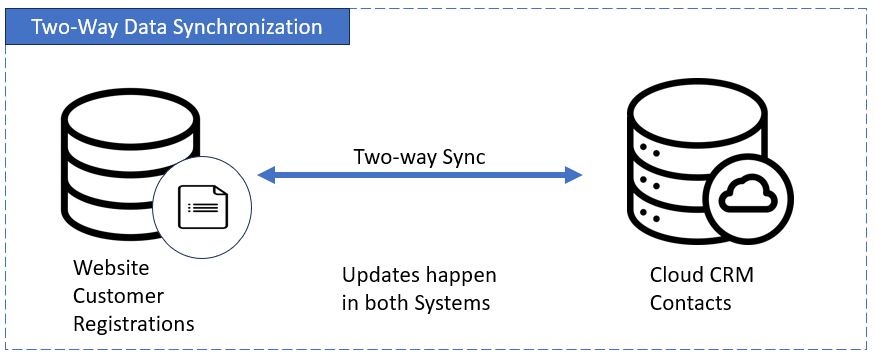
Two-Way Synchronization
This is a two-sided exchange. Data gets updated in both systems. If something changes in System A, System B gets the update and the other way around.
 When it fits best:
When it fits best:
Perfect for tools that share the same data and need to stay in sync, like a CRM and a support app.
Example:Update a customer’s email in Salesforce, and it updates in Zendesk too.
Multi-Way Synchronization
Now we’re talking about syncing across more than two systems. Multi-way sync keeps multiple tools updated with the latest changes, no matter where those changes happen.
When it fits best:Useful for companies that use lots of apps across different teams or departments.
Example:Marketing updates a lead in HubSpot. Sales sees it in Salesforce. Finance sees it in NetSuite. Everyone’s on the same page.
Hybrid Synchronization
Hybrid sync is a mix-and-match. Some data moves both ways, while other data might only go one way or stay read-only.
When it fits best:You want tight control. Maybe only certain fields should be editable across systems.
Example:Contacts can be updated in either app, but order history only flows one way from the ERP system to the CRM.
By Timing
Now let’s talk about when the data gets moved. Is it instant? Or on a schedule?
Real-Time Data Synchronization
Real-time data synchronization means updates happen the moment data changes. It’s like getting a text message the second someone hits send.
When it fits best:Great for apps that need to reflect changes right away, like live dashboards or customer-facing tools.
Example:A customer updates their payment info on your website. The billing system gets the change instantly, so support doesn’t miss a beat.
Batch Data Synchronization
With batch sync, updates happen in bulk, usually on a schedule, like every hour or once a day. Think of it like sending the mail instead of a text.
When it fits best:Perfect when speed isn’t critical and when dealing with large amounts of data.
Example:Product reviews from a website are synced to an analytics tool every midnight.
Quick Comparison Table
Here’s a side-by-side view to help make things clearer:
| Type | Direction | Timing | Best Use Case | Example |
|---|---|---|---|---|
| One-Way Sync | One-way | Real-time or Batch | Sending data downstream without needign replies | Orders sent from e-commerce site to data warehouse |
| Two-Way Sync | Two-way | Usually Real-time | Keeping systems in sync with each other | CRM and support tool updating customer info both ways |
| Multi-Way Sync | Many-to-many | Real-time or Batch | Sharing updates across several connected tools | CRM, ERP, and marketing platform syncing shared records |
| Hybrid Sync | Mixed (some one or two) | Varies | Complex workflows that need more control | Contacts sync two ways; orders flow one way from ERP to CRM |
| Real-Time Sync | Varies | Real-time | Apps needing live updates | Billing info updated instantly across systems |
| Batch Sync | Varies | Scheduled | Handling big data sets when speed isn’t essential | Daily feedback sent to analytics at the end of each day |
Techniques That Power Data Synchronization
Modern data sync isn’t just about moving data from Point A to Point B. It’s about doing it efficiently, accurately, and in a way that fits how the business runs. There are different techniques that make this possible. We’ll break them down into two categories:
-
Based on Sync Volume (What gets synced). The strategy behind how much data is moving.
-
Based on Sync Activation (How syncing is triggered). The way the sync process kicks off.
Based on Sync Volume
These techniques decide how much data is being moved during a sync job.
Full Sync
Full sync copies everything from the source: every row, every column, no matter if it changed or not.
When it’s used:It’s useful when data sets are small or when accuracy is more important than speed. Also common during initial syncs or occasional full refreshes.
What it powers:This is often used in batch sync processes or one-way sync setups.
Example:A retail analytics tool pulls all product data every night to refresh inventory reports, even if nothing changed. It’s simple, but not ideal for big data sets.
Incremental Sync
Only grabs data that’s new or changed since the last sync, usually using a column like LastModifiedDate or a timestamp.
When it’s used:Perfect for large tables where full sync would be too heavy. Widely used in ETL pipelines and cloud data sync jobs.
What it powers:Supports batch or scheduled pull-based syncs, often in one-way or hybrid sync models.
Example:A CRM exports only the contacts added or updated in the last 24 hours to the marketing automation platform.
Change Data Capture (CDC)
CDC tracks row-level changes (inserts, updates, and deletes) by reading database logs, not just timestamps. It’s a smarter, more granular way to sync.
When it’s used:When real-time or near-real-time updates are needed, and especially when deletes must be tracked, too.
What it powers:Common in real-time two-way or hybrid data sync scenarios.
Example:A financial system uses CDC to update account balances and remove closed accounts in a reporting system, almost instantly after changes.
Based on Sync Activation
This category is about what starts the sync, whether it’s pulled, pushed, or triggered by an event.
Pull-Based Sync
The destination system asks the source for data, usually on a schedule.
When it’s used:In classic batch ETL jobs or when systems don’t support real-time push. It’s predictable but might miss rapid changes.
What it powers:Used with incremental syncs or full syncs, often in batch or one-way flows.
Example:An e-commerce platform pulls customer data from the ERP system every hour to update shipping info.
Push-Based Sync
The source system sends data to the destination as soon as changes happen.
When it’s used:When low latency is needed and the source supports webhooks or API triggers.
What it powers:Common in event-driven or real-time sync setups.
Example:A customer support app pushes ticket updates to the CRM the moment an agent changes the ticket status.
Event-Based Sync
Syncs are triggered by specific system events, like a sale happening or a user signing up. Often part of a real-time, event-driven architecture.
When it's used:In modern microservices or serverless apps that need fast, responsive data flow.
What it powers:Often used with CDC, push, or hybrid sync flows.
Example:A streaming app sends a “new subscription” event that updates the billing platform and analytics dashboards instantly.
Techniques That Power Data Synchronization – At a Glance
Below is a comparison table of the techniques we discussed:
| Technique | Category | What It Does | When To Use | Sync Type | Example |
|---|---|---|---|---|---|
| Full Sync | Sync Volume | Syncs the entire dataset, every time | Initial loads, small datasets, simple refresh | Batch, One-way | Sync all product data nightly to rebuild reports |
| Incremental Sync | Sync Volume | Syncs only records added or changed since the last sync | Large datasets, frequent changes, timestamp columns available | Batch, One-way, Hybrid | Export only updated CRM contacts to marketing tool |
| CDC (Change Data Capture) | Sync Volume | Captures real-time inserts, updates, deletes from logs | Real-time sync, when deletes matter, complex tracking needed | Real-time, Two-way, Hybrid | Instantly update dashboards with new or removed financial transactions |
| Pull-Based Sync | Sync Activation | Destination requests data from source on a schedule | Predictable needs, no webhook support | Batch, One-way, Hybrid | ERP system pulls customer updates from sales app hourly |
| Push-Based Sync | Sync Activation | Source sends data immediately when changes happen | When low latency is required, webhook-ready sources | Real-time, One-way or Two-way | CRM pushes lead updates to email platform in real time |
| Event-Based Sync | Sync Activation | Sync triggered by specific business events | Event-driven architecture, microservices, automation-heavy | Real-time, Hybrid | New subscription event triggers updates to billing and analytics platforms |
Data Synchronization Methods
When we talk about syncing data, we’re not just referring to databases. There are different ways it happens depending on the system or use case. Whether it’s syncing files between devices, keeping code changes aligned, or mirroring entire datasets, each method plays a role in keeping data consistent.
Let’s look at the most common methods used today.
File Synchronization
This method keeps files up to date between two or more devices or systems. If someone edits a file in one place, the changes reflect everywhere else that file exists. It’s like making sure everyone’s looking at the same version. No more confusion over “final_final2.docx.”
File sync can be automatic (like using Dropbox or OneDrive) or manual, when a user pushes the updates.
Example: A sales rep works from both a work laptop and a home PC. She edits a proposal document at home. So, the next morning, it’s already available on her office laptop. That’s file sync in action.
Version Control Systems
This one’s a favorite among developers. Version control systems (like Git) don’t just sync files—they track changes over time. They can go back to older versions, branch off for new features, and merge changes later. It’s sync with memory and control.
It’s especially handy when multiple people are working on the same files and edits are managed without overwriting each other.
Example: Two developers are working on the same app feature. One updates the login logic, another fixes a typo. Git keeps track of both and lets them merge changes without losing anything.
Database Synchronization
This method keeps data consistent across multiple databases. This is best when one or more systems need to share data, like a website and a back-end CRM. If a user updates their email in one place, it needs to be accurate everywhere.
Database sync can be one-way (like replication), two-way, or even real-time depending on requirements.
Example: A hospital’s patient portal and internal medical records system both store patient info. If someone updates their address on the portal, the system updates the record in the main database too.
Distributed File Systems
These systems manage files distributed across various servers or locations, creating the illusion of a unified data repository. In reality, the data is stored in segments globally. Synchronization ensures that these chunks remain consistent.
They’re built for scale. Big companies or cloud services often use them behind the scenes.
Example: When someone uploads a photo to a cloud platform like Google Drive, that file might live on multiple servers. A distributed file system syncs those servers so we always see the latest version, no matter where we log in from.
Mirror Computing (Data Mirroring)
This one’s all about redundancy and failover. Mirroring creates an exact copy of data on another system, usually in real-time. If the main system crashes, the mirror kicks in and takes over. It’s less about editing and more about backup and resilience.
Example: A bank mirrors its live transaction database to a backup system in another region. If the main system goes down due to a power outage, the mirrored system steps in instantly, and no data is lost.
Challenges in Data Synchronization
Data synchronization sounds great on paper, until reality kicks in. Systems don’t always play nice. Data doesn’t always arrive on time. And sometimes, things just break for no clear reason. Below are the most common roadblocks teams face when syncing data across platforms, clouds, and regions.
We’ll tackle each of these in the Best Practices section, but for now, here’s what to watch out for:
Latency and Delay
Sometimes, data doesn’t sync right away. There’s a lag. That means dashboards, reports, or systems might run on outdated info just when the boss need real-time insight.
Example: A retail store updates inventory in the warehouse system, but the website still shows items as available for several minutes. A customer places an order… and it turns into a support ticket.
Conflict Resolution
What happens when two systems update the same record differently at the same time? That’s a conflict, and if there’s no clear “winner,” things can get messy.
Example: A customer updates their email address in the billing portal while support updates it differently in the CRM. Which one should be trusted?
Schema Mismatches
Different systems structure data in different ways. One might store a full name in a single field; another breaks it into first and last. Syncing this can lead to data loss or misinterpretation if not handled carefully.
Example: An HR system sends job titles in a dropdown format, but the other app expects free text. Fields might not map correctly or fail to import.
API Limits and Connectivity
APIs are the backbone of most integrations, but they come with rules—like rate limits. Too many requests in too short a time? You’re blocked. And if there’s a network hiccup, syncs can fail altogether.
Example: A marketing platform’s API allows 1000 calls per hour. But your sync job hits that halfway, and the rest gets cut off.
Data Quality
Syncing bad data only makes things worse. If the source system has duplicates, missing fields, or inconsistent formats, those issues carry over or even multiply.
Example: A CRM record with no email address gets synced to an email marketing tool. It shows up in reports but can’t be messaged, skewing the campaign metrics.
Security and Compliance
When data crosses systems, especially across regions or third-party platforms, it introduces risk. Sensitive info like customer data needs handling with care or it faces compliance issues.
Example: Syncing health records across systems without proper encryption could break HIPAA rules, leading to legal trouble and reputational damage.
Best Practices for Effective Data Synchronization
Even with the best tools in place, syncing data isn’t “set and forget.” Follow a few solid practices to make sure everything runs smoothly. Think of this as a safety net that helps avoid the usual headaches like delays, errors, and mismatched data. Below are the best practices that keep syncs clean, reliable, and hassle-free.
Choose a Single Source of Truth
Decide which system holds the final say. Without that, data can bounce back and forth between platforms, changing every time, and nobody knows which version is right.
What challenge it solves: This helps fix conflict resolution problems and reduces data quality issues caused by constant overwrites or duplicate updates.
Example: A CRM pulls customer info from multiple tools: support chat, billing, and email lists. By setting the CRM as the single source of truth, any updates in other systems get validated or overwritten by what’s in the CRM. Everyone’s looking at the same, clean record.
Use Timestamp or CDC Columns
Add “last updated” timestamps or change data capture columns to data tables. That way, only what’s new or changed syncs. No more wasting time on the full dataset every time.
What challenge it solves: This helps reduce latency and delay, avoids API rate limits, and keeps sync jobs fast and efficient.
Example: A SaaS company tracks the last_modified column in its customer table. Every sync job checks only for rows updated after the last run, cutting sync time from 30 minutes to just 2.
Monitor Sync Jobs and Set Alerts
Don’t wait for users to report problems. Use automated monitoring to track sync jobs and alert someone in the team if something breaks, slows down, or fails entirely.
What challenge it solves: This tackles latency, connectivity issues and keeps data quality problems away.
Example: A healthcare company sets up alerts for a nightly patient record sync. If the job takes more than 10 minutes or fails, IT gets notified immediately before doctors see outdated charts in the morning.
Implement Error Handling and Retries
Failures will happen. What matters is how your system reacts. Good sync setups don’t just fail silently. They retry, log the error, and keep going where they left off.
What challenge it solves: This addresses API limits, connectivity issues and reduces data loss from failed jobs.
Example: An e-commerce sync job hits an API rate limit. Instead of stopping everything, it retries the failed requests after a delay and logs them for review. Orders keep flowing in without disruption.
Prefer Real-Time Sync for Critical Workflows
Not everything needs to be synced in real time. But for workflows where speed matters, like customer transactions or live dashboards, batch just won’t cut it.
What challenge it solves: This directly solves latency and delay, and ensures teams act on fresh, reliable data.
Example: A bank uses real-time sync for fraud detection. As soon as a suspicious transaction appears, it gets pushed to the risk engine. No waiting. No gaps. Just fast response when it counts.
Advanced Concepts in Data Synchronization
Conflicts, scale, and reliability are where simple syncs grow teeth. Below are the practical patterns teams lean on when things get busy and messy.
Data Conflict Resolution Strategies
A conflict pops up when the same record gets changed in two places before the next sync lands. Without a plan, you'll quietly overwrite good data or ship contradictions downstream.
What it solves: stops the "two users edit the same field" problem from turning into silent data loss. Think of two reps changing a customer's phone number at the same time. One change shouldn't just vanish.
Common Strategies
Last-In Wins
The newest timestamp wins and overwrites the older value. It's dead simple, quick to implement, and fine for low-risk fields. The catch: "newer" doesn't always mean "more accurate," so use it with care.
Source of Truth Priority
Pick one system as your source of truth. If two updates collide, that system's value wins and serves as the tie-breaker. It's a clean way to keep ownership clear and auditing simple. You still push changes to the other systems. They just take their cues from the master.
Manual Intervention
- Flag the clash.
- Route it to a review queue.
- Let a data steward decide.
It's slower, but for sensitive data or high-value customers, a quick human check beats an automated mistake.
Field-Level Merging
Merge non-overlapping field changes from both sides into one record. It's smarter and keeps more signal, but you'll need good change tracking, clear tie-breakers, and careful testing.
Performance Tuning for Large Datasets
When you're pushing millions of rows, efficiency makes or breaks the run. Poor tuning leads to timeouts, API throttling, and cranky databases.
What it solves: gets big syncs over the line quickly and safely without hammering source systems.
Key Techniques
Indexing Key Columns
Index the columns you filter on most. Last_modified_date, updated_at, primary keys. That one tweak can turn slow scans into snappy lookups.
Optimizing Batch Sizes
Move records in batches, not one by one. Find the sweet spot for your stack: too small and you waste round trips; too large and you risk timeouts or API rate caps. Start mid-range, measure, then nudge up or down.
Parallel Processing
Split the workload and run multiple workers in parallel by ID ranges, shards, or time windows. Add backpressure and concurrency limits so you don't overwhelm APIs or your target database.
Ensuring Transactional Integrity and Idempotency
These two ideas keep pipelines trustworthy when failures happen, and we all know they will.
Transactional Integrity
All or nothing. If step 3 of 5 blows up, you roll the whole thing back so you don’t leave half-baked records lying around. In practice, wrap multi-step writes in transactions or stage first, validate, then commit in one go.
Idempotency
Same operation, same outcome, even if it runs twice. Use natural keys or upserts, dedupe tokens, and safe retry logic so a network blip doesn’t create duplicates or double-charge updates. This is what lets you retry confidently and sleep at night.
How Data Synchronization Works (Step-by-Step)
Data sync may sound like simple file copying. But it’s much more of an engineering process.
To break it down, let’s walk through how a typical database sync works step by step. We’ll use a simple scenario: syncing customer info from an e-commerce system to a CRM. This makes each step feel more real.
Step 1: Decide What to Sync
Before anything moves, be clear on what to sync. Is it all data? Just recent changes? Specific fields?
Don’t sync unnecessary stuff. It wastes time and bandwidth.
Example: Your company decides to sync only the customer names and contact details that were updated in the last 24 hours.
Step 2: Detect Changes
Next, figure out what changed. Did someone update their email? Add a new address?
This step usually depends on timestamps or change tracking columns.
Example: A database table has a last_updated column. Pull only the customer rows where that timestamp is newer than the last sync.
Step 3: Clean and Prepare the Data
Data usually needs a bit of cleanup before it moves. You might need to reformat fields, split up full names, or map columns between systems.
Example: A CRM separates first and last names, but the e-commerce DB stores them as one. So, split “John Doe” into “John” and “Doe” before sending it over.
Step 4: Move the Data
This is the actual "sync" part where data moves from one system to the other. It could happen through an API, a database connection, or a scheduled script.
Example: An API call is used to push customer updates into the CRM. The job runs automatically every hour.
Step 5: Deal with Conflicts or Errors
Sometimes, things clash. Maybe a customer’s email changed in both systems. Or maybe the sync failed halfway through. This is where error handling, conflict resolution rules, and retries come into play.
Example: A data sync process checks which system has the latest update and keeps that version. Failed updates are logged and retried in the next job.
Step 6: Confirm It Worked
Once the sync job runs, did it actually do its job? That means logging results and alerting the team if something went wrong.
Example: Log the number of records updated, skipped, or failed. If more than 10 fail, the sync job sends a Slack alert to the dev team.
Choosing the Right Data Synchronization Tool: What to Look For
Before you pick a sync tool, cut through the noise and boil it down to how fast you can get value without painting yourself into a corner. Zero in on the big-ticket items that make or break day-to-day work:
- Can non-developers stand it up?
- Do the connectors actually cover the stack?
- Will it scale when you crank things up?
Ensure it plays nicely with the security rules and provides clean ways to identify issues, retry safely, and track jobs.
Ease of Use
Start with how quickly a non-developer can set up a working sync. Low-code/no-code tools shine when you need drag-and-drop mapping, guided wizards, and readable run logs. Custom code gives you infinite flexibility, but you’ll own version control, deployments, retries, and on-call. A good middle ground is a tool that lets you click to start and drop to SQL/JS when you need precision.
Connectors
Breadth matters, but depth matters more. Look for pre-built connectors that cover your exact objects, custom fields, filters, and associations, as well as sensible handling of API limits and schema drift. Bonus points if there’s a connector SDK for edge systems and a way to integrate files (S3/Drive/FTP) with SaaS and databases in a single pipeline.
Scalability and Performance
You want smooth scaling from thousands to millions of rows without rewrites. Check for incremental extraction/CDC, batching, parallelism, and backpressure controls to prevent crushing source APIs. For near-real-time needs, confirm event or stream support is available. For heavy nightly loads, confirm bulk endpoints and horizontal scaling. Regional deployment options help keep latency and egress costs down.
Security and Compliance
Non-negotiables: encryption in transit and at rest, secrets management, role-based access, SSO/SAML, and audit trails. If you’re in regulated industries, look for SOC 2, ISO 27001, GDPR features (DPA, data residency), and HIPAA options where relevant. Private networking options like IP allowlisting, VPC/Private Link, or an on-prem agent are a big plus for locked-down databases.
Error Handling and Monitoring
Assume things will fail and judge the tool by how it fails. You want clear run history, row-level error logs, retries with backoff, idempotency to prevent dupes, and easy replay of just the bad records. Real-time alerts to Slack, email, or PagerDuty keep teams in the loop, and dashboards with throughput, lag, and latency help you spot issues before users do.
How Skyvia Solves Data Synchronization Challenges
Skyvia is a no-code data integration platform that lets you set up reliable syncs without writing scripts or babysitting cron jobs. You connect your systems, map the fields, set the rules, and let it run. If you need to dial things in later, you can tweak mappings and filters on the fly with Skyvia’s visual editor.
Skyvia’s Key Features for Data Synchronization
Connectors
Skyvia ships with over 200 ready-to-use connectors for popular CRMs, ERPs, databases, analytics stacks, and file storage. You can mix SaaS apps’ data with cloud or on-prem databases in one pipeline and handle custom fields and objects without custom code.
One-way and two-way sync
Pick your direction and get going.
- One-way for clean downstream feeds.
- Two-way when teams update data in multiple systems.
Conflict rules are easy to set, so you decide which side wins when records collide.
Scheduling that fits your cadence
Run near real time when you need quick turnarounds, or batch on a timetable for heavy nightly moves. You can start small and then scale up as the volume grows, without needing to re-architect.
Error handling and visibility
When something goes sideways, Skyvia doesn’t leave you guessing. You get clear run history, row-level error logs, retries with backoff, and notifications to email, so you can jump in, fix, and replay only what failed.
Ready to synchronize your data with ease? Try Skyvia for free and see how our no-code platform can help you achieve data consistency in minutes.

Data Synchronization Tools
There’s no need to build everything from scratch. Plenty of tools out there can handle data syncs, saving time, reducing errors, and keeping things running smoothly behind the scenes.
Let’s look at a few popular options. Each one brings something different to the table.
Skyvia
Skyvia makes syncing data between cloud apps and databases feel easy. It’s no-code, so even non-developers can set up sync flows fast. Just pick the source, set the target, and Skyvia takes care of the rest.
When to use it: When syncing CRM like HubSpot with a database, or moving data between cloud apps like HubSpot, Google Sheets, or BigQuery—without writing a single line of code.
Example: A sales team updates contacts in HubSpot. The updates show up in an internal MySQL database every hour. Skyvia makes that happen on a schedule.
Talend
Talend is powerful but also more technical. It gives fine control over data pipelines and sync logic. It’s best for teams with complex data needs and someone technical on board.
When to use it: When dealing with large-scale data workflows, custom transformations, or syncing across hybrid environments.
Example: Customer orders are in a legacy system. You want to sync that with a modern analytics platform every day. Talend transforms and loads that data cleanly.
HubSpot Data Sync
HubSpot Data Sync connects HubSpot with popular CRMs and tools like Salesforce, Microsoft Dynamics, and Zendesk. It focuses on contact, company, and deal data.
When to use it: You’re a HubSpot user and want data to flow back and forth between HubSpot and your CRM automatically, no dev work needed.
Example: A lead updates their contact details in Salesforce. HubSpot picks it up and reflects the same changes in its records—within minutes.
Apache NiFi
Apache NiFi gives real-time data movement with visual flow design. It’s open-source and great for data engineers who want control and traceability.
When to use it: When routing, transforming, and syncing data from many sources: APIs, files, and databases in real time or batch.
Example: Your retail stores send sensor data to a central system. NiFi ingests that from multiple edge devices, enriches it, and syncs it to your analytics system as it happens.
Airbyte
Airbyte helps pull data from many sources and push it into a data warehouse. It supports full and incremental sync and works with modern data stacks.
When to use it: For a flexible, open-source solution to sync data into Snowflake, BigQuery, or similar platforms, with built-in support for CDC and scheduling.
Example: You want to pull data from Stripe, Shopify, and Google Ads and load it into Snowflake every 15 minutes. Airbyte handles that flow reliably.
Conclusion
Data sync is how you keep one version of the truth when your business runs on a stack of apps. We nailed down a plain-English definition, walked through common patterns and conflict-resolution tactics, and called out the nuts and bolts that make big jobs finish on time: indexing, smart batching, and parallel runs. We also touched on reliability basics like transactions and idempotency, plus a practical checklist for choosing tools that won’t box you in.
If you prefer to click instead of code, platforms like Skyvia help stand up one-way or two-way syncs, schedule them, and keep tabs on errors without babysitting scripts.
Looking ahead, sync only gets more critical. As teams spread out, data volumes climb, and APIs keep changing under our feet, the winners will be the orgs that wire up clean pipelines, catch conflicts early, and monitor jobs like a hawk.
Nail those habits now, and you’ll ship faster, cut rework, and keep decisions anchored to fresh, trustworthy data.
FAQ
What is the main difference between one-way and two-way sync?One-way pushes changes from a source to a target only. Two-way propagates changes in both directions and needs conflict rules to decide which update wins.
How often should I synchronize my data?Match it to business needs: real-time or near-real-time for ops, hourly/daily for analytics. Start with critical objects more often; batch the rest.
Is data synchronization the same as a data backup?No. Backup is a point-in-time copy for recovery. Sync keeps multiple systems consistent. Most teams need both.
What is the most common challenge in data synchronization?Handling conflicts and change drift (schema or API limits). Without clear rules and monitoring, duplicates and overwrites creep in.
Can data synchronization directly improve my company's ROI?Yes. Fewer manual fixes, faster decisions, and cleaner customer data reduce costs and lift revenue. The gains show up once you design, monitor, and iterate.